[Kubernetes] Kubernetes 실전 설정 및 활용 방법
Intro
안녕하세요, Noah입니다.
이번 글에서는 Kubernetes가 무엇인지 냄새를 맡아보는 시간입니다. 쿠버네티스와 도커를 통해 애플리케이션을 배포하고 관리하는 과정을 다루고자 합니다.
처음 Kubernetes를 설치하고 클러스터를 설정하는 단계부터 배포, 모니터링, 스케일링, 업데이트, 롤백, 그리고 로깅까지 실무에서 꼭 필요한 핵심 기능들을 자세히 설명해보겠습니다.
Kubernetes를 처음 사용하는 분들이나 실무에서 자주 마주치는 문제를 해결하고자 하는 분들에게 유용한 참고 자료가 됐으면 좋겠습니다.
아 그리고 명령어들이 계속 중복해서 등장하는데, 계속 치시면서 같이 따라오시다보면, 어떤 명령어가 어떤 기능을 하는 구나~ 하는 감을 익히도록 일부러 중복되게 설명 적어두었습니다!
아마… Kafka 글에 이어 분량 조절 실패할 것 같은 글이지만, 목차라도 잘 구분해서 적어보겠습니다 ㅎㅎ
(급하신 분들은 Kubernetes 클러스터에 배포 및 모니터링 방법 부터 보시면 될 것 같아요.)
그럼 시작해 보겠습니다.
목차
- Kubernetes를 활용 전 준비할 내용
- Kubernetes 클러스터에 배포 및 모니터링 방법
- Outro
Kubernetes를 활용 전 준비할 내용
기본 개념
1. Kubernetes 구성 요소
쿠버네티스(Kubernetes)는 클라우드 환경에서 애플리케이션을 자동으로 배포, 확장, 관리할 수 있는 오픈소스 플랫폼입니다.
이를 통해 애플리케이션을 손쉽게 컨테이너화하고, 대규모 트래픽이나 다양한 환경 변화에 따라 유연하게 확장하거나 축소할 수 있습니다.
이러한 쿠버네티스는 여러 주요 구성 요소로 이루어져 있으며, 각각의 역할이 독립적이면서도 상호작용을 통해 전체적인 클러스터 환경을 구축하고 관리하는 데 기여합니다.
아래는 주요 구성 요소와 그 역할에 대한 이미지입니다. 지금은 잘 이해 안되도 아래 적어둔 개념들과 이미지를 비교하면서 보시면 이해가 좀 더 빠르실 것 같습니다.
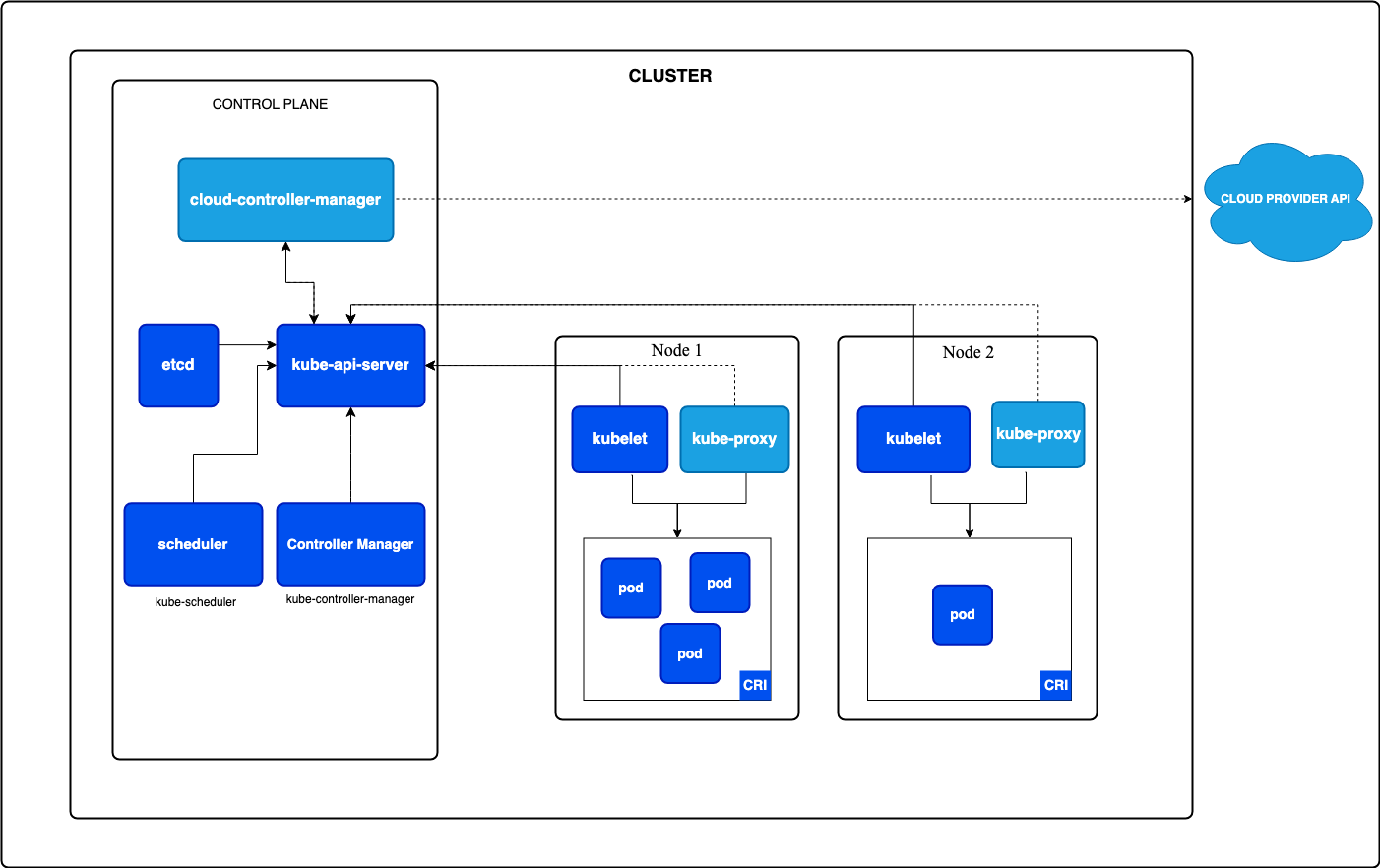 [출처: 쿠버네티스 공식 문서]
[출처: 쿠버네티스 공식 문서]
1-1. 클러스터 (Cluster)
클러스터는 쿠버네티스의 가장 기본적인 단위로, 여러 개의 서버(노드)가 모여서 하나의 큰 시스템처럼 작동하는 환경입니다.
이 클러스터는 쿠버네티스에서 애플리케이션을 실행하고 관리하는 단위이며, 클러스터 내의 자원(노드, 파드 등)은 쿠버네티스에 의해 자동으로 조율됩니다.
1-2. 노드 (Node)
노드는 클러스터를 구성하는 개별 서버입니다.
하나의 클러스터는 여러 개의 노드로 이루어질 수 있으며, 각각의 노드는 실제로 애플리케이션이 실행되는 물리적 또는 가상 머신입니다.
[노드의 두 가지 유형]
- 마스터 노드 (Master Node): 클러스터를 제어하고 관리하는 노드로, 클러스터의 모든 작업을 조정합니다.
마스터 노드는 API 서버, 컨트롤러 매니저, 스케줄러 등으로 구성되어 있으며, 클러스터 내 자원 배치와 상태를 관리합니다. - 워커 노드 (Worker Node): 애플리케이션이 실제로 실행되는 노드로, 파드(Pod)가 배포되어 실행됩니다.
마스터 노드의 지시에 따라 각 컨테이너가 배포되고 관리됩니다.
1-3. API 서버 (API Server)
API 서버는 쿠버네티스 클러스터의 진입점 역할을 합니다.
사용자가 클러스터에 명령을 내리기 위해 가장 먼저 접근하는 요소로, 클러스터 관리와 관련된 모든 요청을 받고, 이 요청을 적절하게 처리하여 다른 구성 요소에 전달합니다.
모든 통신은 API 서버를 통해 이루어지며, API 서버는 클러스터의 중심적인 소통 창구 역할을 합니다.
1-4. etcd
etcd는 클러스터의 모든 설정과 상태 정보를 저장하는 분산 키-값 저장소입니다.
클러스터 내에서 발생하는 모든 데이터가 etcd에 저장되며, 이를 통해 클러스터의 상태를 복구하거나 백업할 수 있습니다.
etcd는 고가용성을 위해 여러 노드에 분산 배치할 수 있으며, 클러스터의 모든 정보를 안정적으로 관리하는 데 핵심적인 역할을 합니다.
1-5. 컨트롤러 매니저 (Controller Manager)
컨트롤러 매니저는 클러스터 내의 다양한 리소스(자원)의 상태를 루프(Loop) 방식으로 지속적으로 모니터링하고, 사용자가 원하는 상태(desired state)로 유지되도록 자동으로 관리하는 역할을 수행하는 핵심 구성 요소입니다. 쿠버네티스에서 사용자는 애플리케이션이나 자원이 어떤 상태가 되어야 한다는 의도를 설정하게 되며, 컨트롤러 매니저는 이러한 설정에 따라 실제 상태(actual state)를 조정해 줍니다. 예를 들어, 애플리케이션이 실행되는 파드가 무언가 오류로 인해 종료되면, 컨트롤러 매니저가 이를 감지하여 새로운 파드를 생성해 애플리케이션의 가용성을 유지하는 방식입니다.
[주요 컨트롤러]
컨트롤러 매니저는 여러 개의 컨트롤러로 이루어져 있으며, 각각의 컨트롤러는 특정 자원에 대해 관리 역할을 합니다.
이러한 컨트롤러들은 특정 자원의 상태를 주기적으로 확인하며, 문제가 발생하거나 설정된 상태와 다를 경우 이를 자동으로 수정합니다.
- 노드 컨트롤러 (Node Controller)
- 노드 컨트롤러는 클러스터에 포함된 각 노드의 상태를 관리하는 역할을 합니다.
- 클러스터 내 노드에 문제가 발생하거나 노드가 비정상적으로 종료되면 이를 감지하여 해당 노드에서 실행 중이던 파드를 다른 노드로 이동시킵니다.
- 또한, 특정 시간 동안 노드와의 통신이 이루어지지 않을 경우, 해당 노드를 클러스터에서 제거하거나 관련 파드를 재배치합니다.
- 레플리케이션 컨트롤러 (Replication Controller)
- 레플리케이션 컨트롤러는 애플리케이션의 파드 개수를 원하는 만큼 유지하는 역할을 합니다.
- 예를 들어, 사용자가 애플리케이션의 파드를 3개로 설정했는데, 무언가 오류로 인해 1개의 파드가 종료되면 레플리케이션 컨트롤러가 자동으로 새로운 파드를 생성해 파드 수를 3개로 유지합니다.
- 이를 통해 애플리케이션의 가용성을 보장하고, 예기치 않은 문제에도 안정적인 서비스를 유지할 수 있습니다.
- 레플리카셋 컨트롤러 (ReplicaSet Controller)
- 레플리카셋은 레플리케이션 컨트롤러와 유사하지만 보다 효율적으로 파드 개수를 관리할 수 있는 컨트롤러입니다.
- 각 파드의 라벨을 기반으로 원하는 수의 파드를 유지하며, 디플로이먼트(Deployment)와 함께 사용하여 특정 버전의 파드 수를 조정하거나 롤아웃하는 데 활용됩니다.
- 엔드포인트 컨트롤러 (Endpoint Controller)
- 엔드포인트 컨트롤러는 서비스와 파드 간의 연결을 관리합니다.
- 서비스가 생성되면 엔드포인트 컨트롤러는 해당 서비스가 접근할 수 있는 파드 목록을 자동으로 업데이트하여, 로드밸런싱 및 통신을 원활히 할 수 있도록 합니다.
- 서비스 어카운트 & 토큰 컨트롤러 (Service Account & Token Controller)
- 클러스터 내 각 파드에 대해 서비스 어카운트와 인증 토큰을 자동으로 생성하여 할당합니다.
- 이로 인해, 파드가 클러스터 내 다른 자원과 상호작용할 때 필요한 인증을 간편하게 수행할 수 있습니다.
- 잡 컨트롤러 (Job Controller)
- 잡 컨트롤러는 주로 일회성 작업을 수행하는 파드를 관리합니다.
- 특정 작업이 완료될 때까지 파드를 실행하고, 작업이 완료되면 파드를 자동으로 종료합니다.
- 스테이트풀셋 컨트롤러 (StatefulSet Controller)
- 스테이트풀셋 컨트롤러는 상태가 중요한 애플리케이션을 관리할 때 사용됩니다.
- 데이터베이스와 같이 순차적 실행 순서와 데이터 상태를 보존해야 하는 애플리케이션의 파드를 생성 및 관리하며, 각 파드에 고유한 아이덴티티를 부여합니다.
1-6. 스케줄러 (Scheduler)
스케줄러는 파드를 어느 노드에 배치할지 결정하는 역할을 합니다.
파드를 생성할 때 클러스터 내 자원을 분석하여, 파드가 원활하게 실행될 수 있는 최적의 노드를 찾습니다.
이는 파드가 요구하는 자원(CPU, 메모리 등)과 노드의 현재 상태를 고려하여 이루어집니다.
1-7. 쿠버네티스 네트워크 (Kubernetes Network)
쿠버네티스는 각 파드와 서비스가 서로 원활하게 통신할 수 있도록 네트워크를 관리합니다.
쿠버네티스의 네트워크는 기본적으로 클러스터 내 모든 파드가 서로 IP를 통해 통신할 수 있도록 구성됩니다.
이 네트워크는 각 파드가 다른 파드나 서비스와 통신할 수 있도록 연결하고, 로드 밸런싱을 통해 트래픽을 분산하여 안정적인 서비스를 유지합니다.
1-8. 서비스 (Service)
서비스는 클러스터 내 파드의 집합에 대한 네트워크 접근 방법을 정의하는 객체입니다.
예를 들어, 웹 애플리케이션의 프론트엔드 파드가 데이터베이스 파드에 접근할 때 서비스가 중간 역할을 하여 서로를 연결해줍니다.
서비스는 파드의 IP 주소가 변경되더라도 클러스터 내에서 안정적인 접근 경로를 제공합니다.
1-9. 파드 (Pod)
파드는 쿠버네티스에서 가장 작은 배포 단위로, 하나 이상의 컨테이너를 포함하는 논리적인 그룹입니다.
파드는 주로 컨테이너를 하나씩 포함하지만, 서로 밀접하게 연관된 작업을 수행하는 여러 개의 컨테이너가 포함될 수도 있습니다.
예를 들어, 웹 서버와 파일 처리 백그라운드 작업을 동시에 수행해야 하는 경우, 이들을 하나의 파드에 배치해 리소스를 공유하며 통신할 수 있게 합니다.
[파드의 특징]
- IP 주소 공유: 파드 내 모든 컨테이너는 동일한 네트워크 네임스페이스에서 작동하므로, 동일한 IP 주소를 공유합니다. 이를 통해 파드 내부 컨테이너 간의 통신이 간단해집니다.
- 스토리지 공유: 파드 내의 모든 컨테이너는
volume이라는 공유 스토리지 자원을 통해 데이터를 공유할 수 있습니다. 예를 들어, 한 컨테이너가 생성한 파일을 다른 컨테이너에서 사용하는 경우 유용합니다. - 수명 주기 관리: 파드는 일시적인 자원으로, 특정 작업이 완료되면 자동으로 삭제될 수 있습니다. 따라서 쿠버네티스는 파드를 필요에 따라 생성, 제거, 재시작하여 애플리케이션의 가용성을 유지합니다.
[pod.yaml 예시]
웹 애플리케이션을 배포한다고 가정해 보겠습니다.
이 웹 애플리케이션은 데이터베이스와 통신해야 하므로, 이를 위해 파드를 설정할 수 있습니다.
apiVersion: v1
kind: Pod
metadata:
name: web-app
spec:
containers:
- name: web-container
image: nginx
ports:
- containerPort: 80
- name: db-container
image: postgres
ports:
- containerPort: 5432
위 YAML 파일에서는 web-app이라는 파드에 nginx와 postgres 컨테이너가 포함됩니다.
이 두 컨테이너는 같은 파드에서 실행되며 네트워크와 스토리지를 공유할 수 있습니다.
하지만, 보통 위처럼 pod.yaml을 별도로 관리하기 보다는 일반적으로 디플로이먼트(Deployment.yaml)나 스테이트풀셋(StatefulSet)과 같은 상위 컨트롤러에 의해 관리됩니다.
2. Kubernetes 라이프사이클
파드는 일반적으로 디플로이먼트(Deployment)와 같은 워크로드 리소스를 통해 관리되며, 이를 통해 파드의 복제, 업데이트, 자동 복구 등이 가능합니다.
쿠버네티스 공식 홈페이지를 방문하면 이런 파드들에 대한 라이프사이클 관리 문서를 확인할 수 있습니다.
쿠버네티스에서 파드(Pod)는 컨테이너를 관리하는 기본 단위로, 각 파드는 정의된 라이프사이클을 따릅니다.
[출처: 쿠버네티스 공식 문서]
[파드의 라이프사이클 단계]
(파드의 상태는 kubectl describe pod <파드명> 명령어를 통해 확인할 수 있습니다.)
- Pending: 파드가 클러스터에 수락되었지만, 하나 이상의 컨테이너가 아직 생성되지 않았거나 준비되지 않은 상태입니다.
이 단계에서는 스케줄링 대기 시간과 이미지 다운로드 시간이 포함됩니다. - Running: 파드가 노드에 바인딩되고, 모든 컨테이너가 생성된 상태입니다. 최소한 하나의 컨테이너가 실행 중이거나 시작 또는 재시작 중입니다.
- Succeeded: 파드 내 모든 컨테이너가 성공적으로 종료되었으며, 재시작되지 않습니다.
- Failed: 파드 내 모든 컨테이너가 종료되었으며, 하나 이상의 컨테이너가 실패로 종료되었습니다.
이는 컨테이너가 비정상 종료되었거나 시스템에 의해 종료되었음을 의미합니다. - Unknown: 파드의 상태를 알 수 없는 경우로, 노드와의 통신 오류 등으로 인해 발생할 수 있습니다.
[파드 내 각 컨테이너의 상태값]
(컨테이너의 상태는 kubectl describe pod <파드명> 명령어를 통해 확인할 수 있으며, 각 상태에 대한 이유와 종료 코드를 제공합니다.)
- Waiting: 컨테이너가 아직 시작되지 않았으며, 필요한 작업(예: 이미지 다운로드)을 수행 중입니다.
- Running: 컨테이너가 정상적으로 실행 중입니다.
- Terminated: 컨테이너가 실행을 마쳤거나 오류로 종료된 상태입니다.
실제 코드로 확인해보기
아래는 파드를 생성하고 종료하는 과정을 코드로 설명한 예제입니다.
2-1. 파드 정의 (YAML 파일)
먼저, 파드 정의 파일(pod-example.yaml)을 작성합니다.
위 YAML 파일은 nginx 이미지를 사용하는 example-pod라는 이름의 파드를 정의합니다. example-container는 80번 포트를 사용하며, 쿠버네티스가 이를 관리합니다.
apiVersion: v1
kind: Pod
metadata:
name: example-pod
labels:
app: example
spec:
containers:
- name: example-container
image: nginx
ports:
- containerPort: 80
2-2. 파드 생성
쿠버네티스 클러스터에 파드를 생성하기 위해 kubectl 명령어를 사용합니다.
이 명령어를 실행하면 쿠버네티스가 pod-example.yaml 파일에 정의된 대로 파드를 생성합니다.
kubectl apply -f pod-example.yaml
2-3. 파드 상태 확인
파드가 정상적으로 실행 중인지 확인하려면 kubectl get pods 명령어를 사용합니다.
kubectl get pods
특정 파드의 상세 상태를 확인하려면 다음과 같은 명령어를 사용할 수 있습니다.
kubectl describe pod example-pod
2-4. 파드 종료
파드를 종료하려면 kubectl delete pod 명령어를 사용하여 생성된 파드를 삭제합니다.
이 명령어는 example-pod라는 이름의 파드를 종료하고, 클러스터에서 삭제합니다.
kubectl delete pod example-pod
2-5. 파드 라이프사이클에 대한 추가 관리
파드 라이프사이클 훅(예: preStop)을 정의하고 싶다면 YAML 파일의 containers 항목에 추가할 수 있습니다.
예를 들어, 파드 종료 전에 특정 명령을 실행하도록 preStop 훅을 추가합니다.
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: nginx
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "echo 'Terminating...'"]
이렇게 하면 파드가 종료되기 직전에 “Terminating…” 메시지를 출력합니다.
위 과정을 통해 쿠버네티스에서 파드를 생성하고 종료하는 기본적인 흐름을 관리할 수 있습니다.
배포를 위한 설정 파일 준비
1. Kubernetes 설치 및 설정
# Kubernetes 클러스터 관리를 위해 kubectl 설치
brew install kubectl
# kubectl의 명령어 자동 완성을 설정하면 명령어 입력이 훨씬 편리해집니다.
# 1. bash 사용자
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ~/.bashrc
# 2. zsh 사용자
source <(kubectl completion zsh)
echo "source <(kubectl completion zsh)" >> ~/.zshrc
2. Docker 이미지 생성하기
- 배포하고 싶은 FastAPI 앱에 대해 Dockerfile을 생성합니다.
# FastAPI로 앱 제작 시 예시 FROM python:3.9 WORKDIR /app COPY . /app # 필요한 패키지 설치 RUN apt-get update && apt-get install -y libgl1-mesa-glx # 의존성 설치 RUN pip install --upgrade pip RUN pip install --no-cache-dir -r requirements.txt # 서비스 실행 CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"] - 명령어를 사용해 이미지를 생성합니다.
# 예시 docker build -t my-fastapi-app:latest .
Kubernetes 설정
1. Kubernetes Deployment 리소스 정의하기(Deployment.yaml)
Kubernetes에서 각 FastAPI 앱을 배포하려면 Deployment와 Service 리소스를 정의합니다.
Deployment 리소스는 FastAPI 앱을 실행하는 Pod을 관리하고, Service 리소스는 Pod에 대한 로드 밸런싱을 제공합니다.
[예시 - 최대 1GB 메모리와 1.0 CPU 코어 설정]
apiVersion: apps/v1
kind: Deployment
metadata:
name: fastapi-app
labels:
app: fastapi-app
spec:
replicas: 1 # 초기 파드 개수
selector:
matchLabels:
app: fastapi-app
template:
metadata:
labels:
app: fastapi-app
spec:
nodeSelector:
role: worker # worker라는 라벨을 가진 노드에 배포 > 자세한건 클러스터 생성 파트에 적어두었습니다.
containers:
- name: fastapi-app
image: my-fastapi-app:latest # 로컬에서 빌드한 이미지 사용
imagePullPolicy: Never # 도커허브에서 이미지를 당겨오지 않고 로컬 이미지를 사용
resources:
requests: # 요청한 최소 리소스
memory: "512Mi" # 최소 512Mb 메모리 요청
cpu: "500m" # 최소 0.5 CPU 코어 요청
limits: # 최대 사용 가능한 리소스
memory: "1Gi" # 최대 1GB 메모리
cpu: "1000m" # 최대 1.0 CPU 코어
ports:
- containerPort: 8000
2. Kubernetes Service 리소스 정의하기(Service.yaml)
Service 리소스는 Deployment 리소스로 생성된 Pod에 대한 로드 밸런싱을 제공합니다.
Pod에 대한 로드 밸런싱을 위해 ClusterIP 타입을 사용하며, NodePort, LoadBalancer 타입도 사용 가능합니다.
[예시1 - ClusterIP 타입]
apiVersion: v1
kind: Service
metadata:
name: fastapi-service
spec:
selector:
app: fastapi-app
ports:
- protocol: TCP
port: 8000 # 서비스 포트
targetPort: 8000 # FastAPI 컨테이너 내부 포트
type: ClusterIP
ClusterIP 타입은 클러스터 내부 통신을 위해 사용되며 외부에서 직접 접근할 수 없습니다. 외부 접근이 필요할 경우 kubectl port-forward 명령어를 사용하여 로컬 호스트의 포트와 서비스 포트를 연결할 수 있습니다.
예를 들어, 로컬 호스트의 포트 37000을 FastAPI 서비스의 포트 8000과 연결하려면 다음과 같이 실행합니다
kubectl port-forward service/fastapi-service 37000:8000
이제 http://localhost:37000으로 접근하여 클러스터 내부의 FastAPI 서비스에 연결할 수 있습니다.
(로컬에서 테스 하실 때는 이 방식이 가장 편합니다~)
[예시2 - NodePort 타입]
NodePort 타입은 클러스터 외부에서 노드의 IP 주소와 고정된 포트를 통해 서비스에 접근할 수 있도록 합니다. 이 타입을 사용하면 클러스터 외부에서 특정 포트를 통해 서비스에 접근할 수 있습니다.
apiVersion: v1
kind: Service
metadata:
name: fastapi-service
spec:
selector:
app: fastapi-app
ports:
- protocol: TCP
port: 80
targetPort: 8000
nodePort: 30007 # NodePort 포트 설정
type: NodePort
위 예시에서는 포트 30007이 NodePort로 설정되었습니다. 이제 노드의 IP 주소와 포트 30007을 통해 외부에서 FastAPI 서비스에 접근할 수 있습니다.
클러스터의 노드 IP 주소가 192.168.1.10이라면 다음 주소를 통해 도커를 통해 배포한 서비스에 접근할 수 있습니다
클러스터 안에서는 이제 http://<해당노드의IP주소>:30007를 통해 접근이 가능해집니다.
주의: 노드의 IP 주소는 클러스터 환경에 따라 다르므로, 각 노드의 실제 IP를 확인해야 합니다.
아래 명령어를 입력하면 INTERNAL-IP가 나옵니다. 해당 IP 주소를 통해 노드에 접근할 수 있습니다.
# 노드IP 주소 확인 방법
kubectl get nodes -o wide

[예시3 - LoadBalancer 타입]
LoadBalancer 타입은 클라우드 환경에서 외부 로드 밸런서를 자동으로 생성하여 서비스에 트래픽을 전달합니다. 이를 통해 클러스터 외부에서 쉽게 접근할 수 있도록 외부 IP 주소를 할당받습니다.
apiVersion: v1
kind: Service
metadata:
name: fastapi-service
spec:
selector:
app: fastapi-app
ports:
- protocol: TCP
port: 80
targetPort: 8000
type: LoadBalancer
이 설정을 사용하면 클라우드 프로바이더(AWS, GCP, Azure 등)가 외부 IP 주소를 할당해 줍니다.
할당된 IP 주소는 kubectl get service fastapi-service 명령어로 확인할 수 있으며, 해당 IP 주소를 통해 외부에서 FastAPI 서비스에 접근 가능합니다.
예를 들어, 할당된 외부 IP가 34.120.0.1이라면, 아래와 같은 주소로 서비스에 접근할 수 있습니다:
http://34.120.0.1:80
참고: 로컬 클러스터 환경에서는 LoadBalancer 타입으로 외부 IP가 할당되지 않을 수 있으며, 이 경우 MetalLB와 같은 LoadBalancer Controller를 설정하여 외부 접근을 지원할 수 있습니다.
3. Horizontal Pod Autoscaler 설정하기
3-1. 스케일 아웃 조건 설정하기
CPU나 메모리 사용량이 50%를 넘으면 자동으로 스케일 아웃되도록 Horizontal Pod Autoscaler(HPA)를 설정합니다.
CPU 사용량을 기반으로 설정할 시 Kubernetes에서 명령어로 쉽게 HPA를 설정할 수 있습니다.
kubectl autoscale deployment fastapi-app --min=3 --max=10 --cpu-percent=50
3-2. 스케일 인 조건 설정
기본적으로 Kubernetes는 리소스 사용량이 줄어들면 자동으로 스케일 인이 되지만, 일정시간 지연 시간을 두고 싶다면 -horizontal-pod-autoscaler-downscale-stabilization 플래그로 시간 조건을 추가할 수 있습니다.
하지만 이렇게 명령어를 사용하는 것 보다는 HPA 리소스 파일을 사용하는 것이 더 재사용성 및 확장성이 높아 권장됩니다.
[예시 - 50% 이하로 내려온 상태로 5분이상 지속될 시 스케일인 진행]
kubectl autoscale deployment fastapi-app --min=3 --max=10 --cpu-percent=50 --horizontal-pod-autoscaler-downscale-stabilization=5m
4. Kubernetes 리소스 파일로 설정 적용하기
deployment.yaml, service.yaml, hpa.yaml와 같은 파일명을 사용할 수 있습니다.
4-1. 파일 구조 예시
project-root/
└── k8s/
├── deployment.yaml # Deployment 관리 파일
├── service.yaml # Service 관리 파일
└── hpa.yaml # Horizontal Pod Autoscaler 관리 파일
4-2. 파일 내용
각 조건을 충족하는 파일들을 아래와 같이 작성할 수 있습니다.
[deployment.yaml (Deployment 설정 파일)]
아래 글을 설정하기 전에 export KUBECONFIG="$(kind get kubeconfig-path --name=<클러스터_이름>)"을 통해 kind의 docker 클러스터 kubectl이 접속 가능해야 합니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: fastapi-app
labels:
app: fastapi-app
spec:
replicas: 1 # 초기 파드 개수
selector:
matchLabels:
app: fastapi-app
template:
metadata:
labels:
app: fastapi-app
spec:
nodeSelector:
role: worker # worker라는 라벨을 가진 노드에 배포 > 자세한건 클러스터 생성 파트에 적어두었습니다.
containers:
- name: fastapi-app
image: my-fastapi-app:latest # 로컬에서 빌드한 이미지 사용
imagePullPolicy: Never # 도커허브에서 이미지를 당겨오지 않고 로컬 이미지를 사용
resources:
requests: # 요청한 최소 리소스
memory: "512Mi" # 최소 512Mb 메모리 요청
cpu: "500m" # 최소 0.5 CPU 코어 요청
limits: # 최대 사용 가능한 리소스
memory: "1Gi" # 최대 1GB 메모리
cpu: "1000m" # 최대 1.0 CPU 코어
ports:
- containerPort: 8000
[service.yaml (Service 설정 파일 > 추후 Service 파트에서 다양한 종류를 다룰 것입니다.)]
apiVersion: v1
kind: Service
metadata:
name: fastapi-service
spec:
selector:
app: fastapi-app
ports:
- protocol: TCP
port: 8000 # 서비스 포트
targetPort: 8000 # FastAPI 컨테이너 내부 포트
type: ClusterIP
[hpa.yaml (Horizontal Pod Autoscaler 설정 파일)]
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: fastapi-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: fastapi-app
minReplicas: 1
maxReplicas: 5
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # 5분 동안 CPU/Memory가 50% 이하로 유지되어야 스케일 인
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # CPU 사용량 50% 이상 시 스케일 아웃
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 50 # Memory 사용량 50% 이상 시 스케일 아웃
4-3. Cluster 생성
kind를 사용하여 클러스터를 커스터마이징하고 싶다면, 다음과 같이 k8s 디렉토리에 kind-config.yaml 파일을 작성하고, 이를 통해 클러스터를 생성할 수 있습니다.
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
위 설정에서는 컨트롤 플레인 노드 1개와 워커 노드 2개가 추가됩니다.
클러스터 생성을 위해 위에서 생성한 설정 파일을 이용해 클러스터를 생성하려면 다음 명령어를 실행하세요.
# Docker Desktop을 사용하는 경우
brew install kind
# kind 클러스터 생성
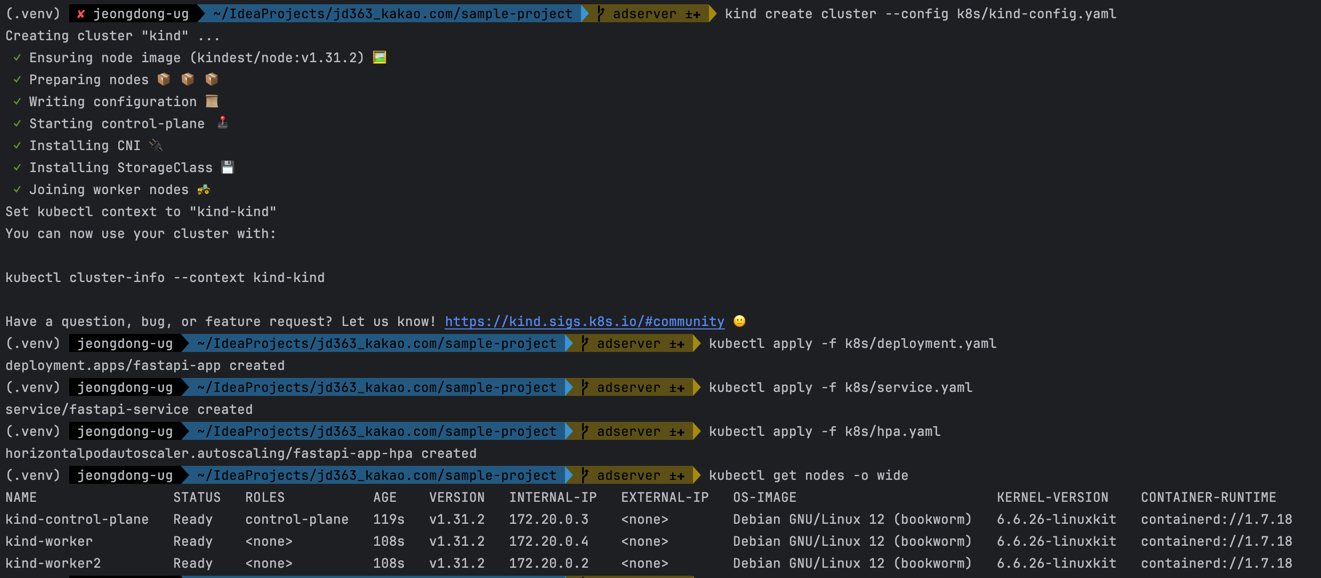
kind create cluster --name my-cluster --config k8s/kind-config.yaml
# 생성여부 확인
kubectl get nodes -o wide
# Deployment에서 사용할 노드에 라벨을 추가합니다. > 이 라벨을 보고 배포가 진행됩니다.
kubectl label nodes my-cluster-worker role=worker
kubectl label nodes my-cluster-worker2 role=worker
4-4. 파일 적용 방법
아래 kubectl 명령어를 사용하여 각각 적용할 수 있습니다.
# Deployment, Service, HPA 리소스 파일 적용
kubectl apply -f k8s/deployment.yaml
kubectl apply -f k8s/service.yaml
kubectl apply -f k8s/hpa.yaml
# 추후 문제가 있을 시 삭제 방법
kubectl delete -f k8s/deployment.yaml
kubectl delete -f k8s/service.yaml
kubectl delete -f k8s/hpa.yaml
Kubernetes 클러스터에 배포 및 모니터링 방법
1. 위 설정 파일 기반으로 Kubernetes 클러스터에 배포하기
설정 파일을 통해 Kubernetes 클러스터에 처음으로 애플리케이션을 배포하는 과정을 안내드리겠습니다.
배포 과정에서 자주 발생하는 문제와 배포 후의 확인 절차도 함께 설명하니, 하나씩 꼼꼼히 따라가시면 됩니다.
1-1 클러스터 초기 준비사항
Kubernetes에 애플리케이션을 배포하기 전 준비가 필요합니다. 배포 준비 과정에서는 아래 사항을 꼭 확인하세요.
- Dockerfile Build 해두기
Docker가 설치되어 있는 상태여야 합니다.
docker build -t my-fastapi-app:latest . - kubectl 설치 확인
kubectl이 설치되어 있고, 클러스터에 연결된 상태여야 합니다.
kubectl version --client이 명령어로
kind클라이언트가 정상적으로 설치되어 있는지 확인하세요. 설치가 되어 있지 않다면, Homebrew를 사용해 설치할 수 있습니다brew install kind이 명령어로
kubectl클라이언트가 정상적으로 설치되어 있는지 확인하세요. 설치가 되어 있지 않다면, Homebrew를 사용해 설치할 수 있습니다brew install kubectl - Kubernetes 클러스터 생성 및 Docker 이미지 로드 방법
아래 명령어를 활용해 클러스터 생성# 클러스터 생성 kind create cluster --name my-cluster --config k8s/kind-config.yaml # 추후 문제가 있을 시 삭제 방법 kind delete cluster --name my-cluster # 생성된 클러스터 확인 kind get clusters kubectl config get-contexts - Kubernetes 클러스터 연결 확인
클러스터와의 연결 상태를 확인해 봅니다. 클러스터의 노드 목록이 출력되면 연결이 잘 된 상태입니다. 노드가 출력되지 않는다면 클러스터 설정을 다시 확인해 주세요.
kubectl get nodes
[실제 예시]
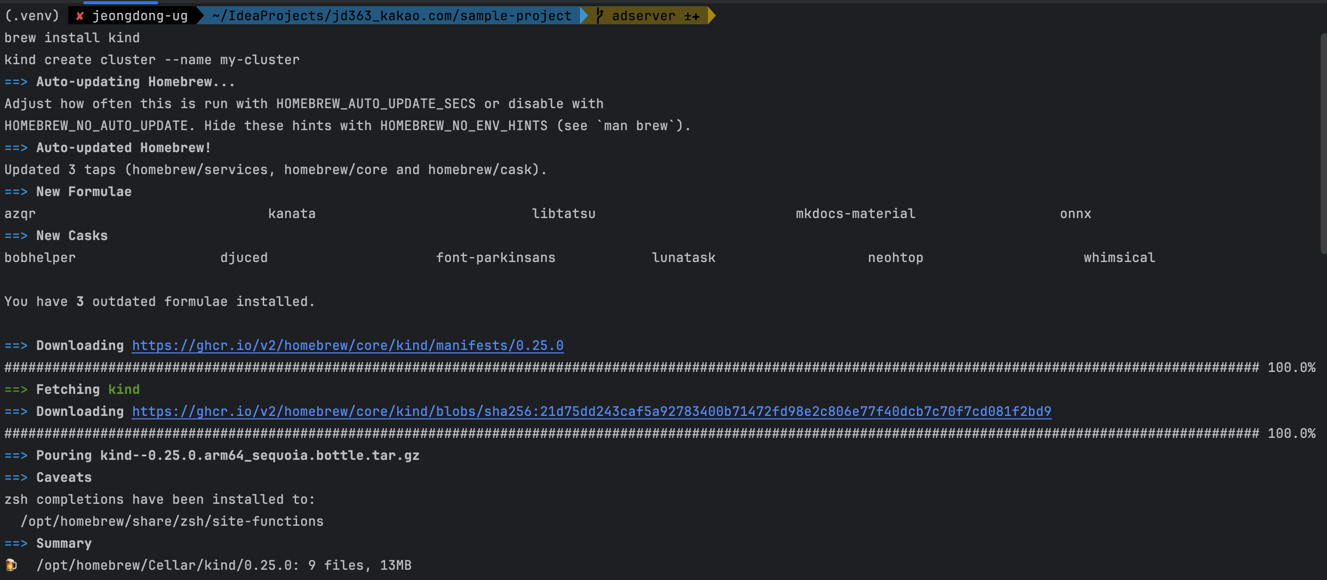
kind를 사용하여 클러스터를 생성하고, kubectl get nodes 명령어로 노드 목록을 확인합니다.
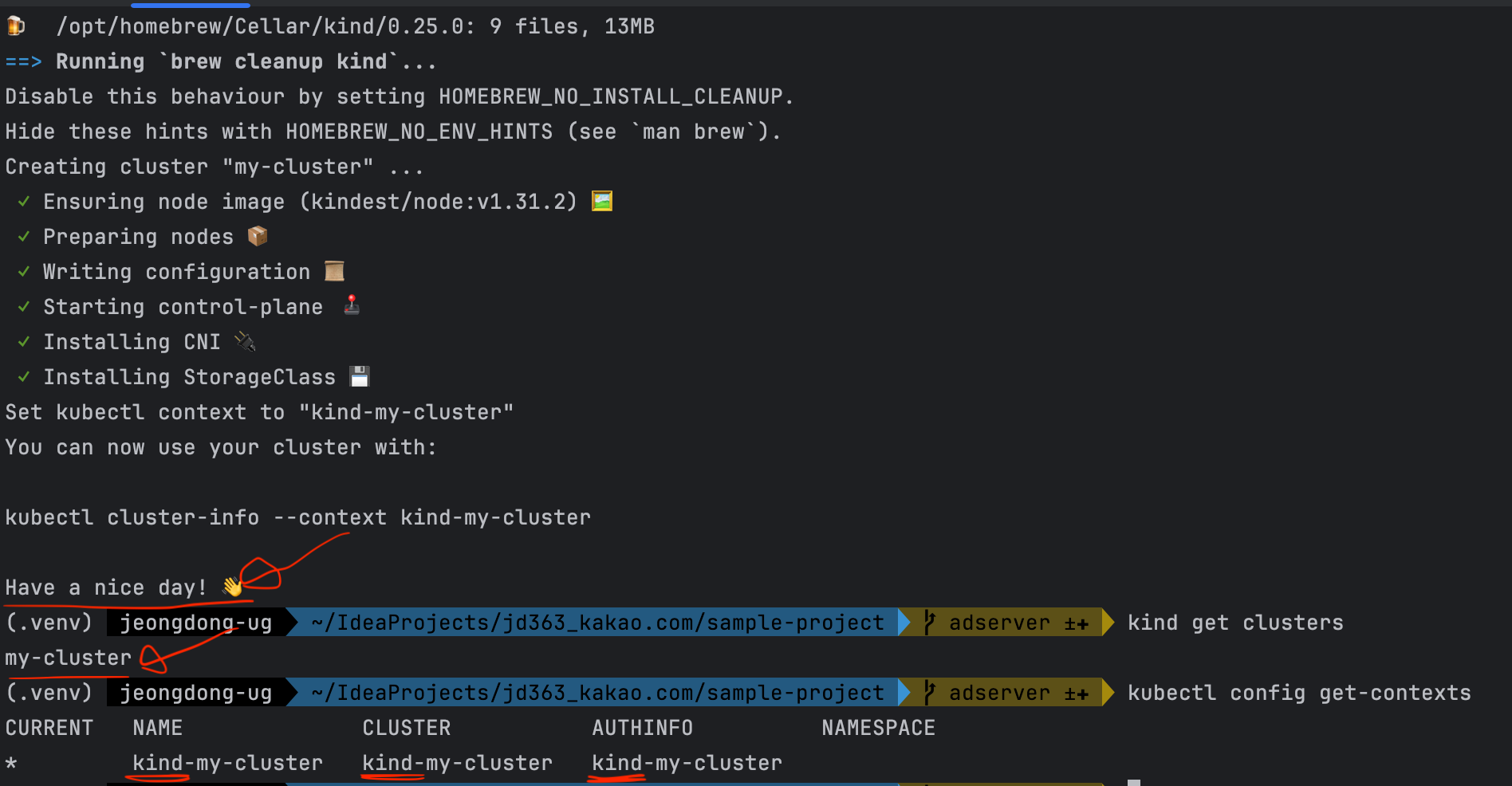
설치되고 나면 위와 같이 확인 가능합니다.

컨트롤 플레인 노드가 마스터 노드라고 생각하면 됩니다 > 상단의 공식 홈페이지 이미지 참조
1-2 배포 파일 구조 재확인
클러스터에 배포할 때, 파일 구조가 정확해야 하며 설정 파일이 올바른 디렉터리에 있어야 합니다.
이 가이드에서는 k8s 폴더에 배포와 관련된 YAML 파일을 저장하도록 했습니다.
이제 YAML 파일을 차례로 kubectl apply 명령어로 클러스터에 적용하겠습니다.
project-root/
└── k8s/
├── deployment.yaml # Deployment 설정 파일
├── service.yaml # Service 설정 파일
└── hpa.yaml # Horizontal Pod Autoscaler 설정 파일
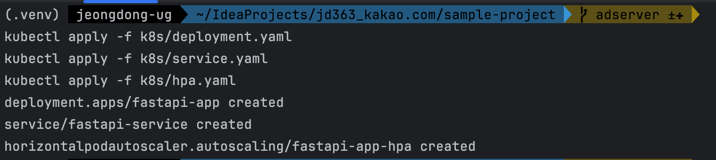
1-3 Deployment 설정 파일 배포하기
- Deployment 적용
먼저deployment.yaml파일을 사용하여 애플리케이션을 배포합니다. 이 파일에는 Pod이 생성될 리소스 제한과 레이블이 포함되어 있어, Kubernetes가 각 Pod을 관리할 수 있도록 합니다.
이 명령어를 실행하면 설정된 Deployment가 클러스터에 적용되며, 지정된 수만큼의 Pod이 생성되기 시작합니다. 여기서 주의해야 할 점은 명령어 실행 후 로그에 오류가 없는지 확인하는 것입니다. 예를 들어, YAML 형식 오류나 잘못된 이미지 태그로 인해 배포가 실패할 수 있습니다. 이러한 오류는 콘솔 로그에 즉시 표시됩니다.
kubectl apply -f k8s/deployment.yaml - Deployment 상태 확인
Deployment가 제대로 적용되었는지 확인하기 위해 다음 명령어를 사용해 상태를 확인하세요.
출력 결과에서 배포가 정상적으로 진행되고 있는지,READY상태가 목표한 Pod 개수와 일치하는지 확인합니다. 만약 Pod 개수가 준비되지 않았다면 이미지 다운로드나 리소스 설정을 다시 확인해야 합니다.
kubectl get deployments
1-4 Service 설정 파일 배포하기
Deployment가 준비되면, 이제 Pod을 외부와 연결해줄 Service 리소스를 설정하겠습니다.
- Service 적용
이 명령어로 Service가 설정되면, Deployment와 연결되어 Pod에 트래픽이 전달될 수 있습니다.
kubectl apply -f k8s/service.yaml - Service 상태 확인
다음 명령어로 Service가 정상적으로 생성되었는지 확인합니다.
여기서CLUSTER-IP와 포트가 올바르게 노출되고 있는지 확인하세요. 특히, 외부 트래픽을 받을 수 있는 NodePort나 LoadBalancer 유형으로 설정하지 않았다면 로컬 네트워크 안에서만 접근 가능합니다.
kubectl get services - Pod 및 Service 연결 확인
Service가 Deployment와 올바르게 연결되었는지,kubectl describe service fastapi-service명령어로 확인할 수 있습니다. Service가 어느 Pod에 트래픽을 라우팅하는지와 포트 정보 등이 나옵니다.
1-5 Horizontal Pod Autoscaler(HPA) 설정 파일 배포하기
이제 트래픽 증가에 대비해 설정한 HPA 파일을 배포합니다. 이 파일은 Pod의 CPU 또는 메모리 사용량에 따라 자동으로 스케일 조절이 가능하도록 합니다.
- HPA 적용
HPA가 설정되면, Kubernetes는 자동으로 리소스 사용량을 모니터링하며 설정된 임계값에 도달할 때 Pod 수를 늘리거나 줄이게 됩니다.
kubectl apply -f k8s/hpa.yaml - HPA 상태 확인: 다음 명령어로 HPA가 올바르게 작동하는지 확인합니다. HPA의
TARGETS열에서 CPU와 메모리 사용률이 설정된 조건에 도달하면 스케일 조정이 진행됩니다. 사용률이 반영되기까지 약간의 시간이 걸릴 수 있으니 1-2분 정도 기다렸다가 확인해 보세요.kubectl get hpa
1-6 배포할 이미지 Kind에 로드하기
Docker 이미지 로드: 본인이 빌드한 도커 이미지를 Kind에 로드 후 kubernetes가 인식할 수 있도록 합니다.
(로컬에서 Docker build 시에는 변경 시 마다 코드를 실행해 주셔야하며, 이렇게 안하면 이미지를 찾을 수 없다는 에러가 발생합니다!!)
kind load docker-image <your-app>:latest --name <cluster-name>
[실제 예시]
# 로컬 Docker 이미지를 kind로 생성한 클러스터에 로딩 시키는 코드
kind load docker-image my-fastapi-app:latest --name my-cluster
# 이미지 로드 확인
kubectl get pods
# 수정된 이미지에 맞춰 Deployment를 다시 적용
kubectl apply -f k8s/deployment.yaml
# 해당 이미지가 로드 되었는지 체크
kubectl get deployments

본인이 빌드한 도커 이미지를 클러스터에 로드

이미지가 정상 실행되었는지 체크
위 과정에서 실수가 있었으면 처음하실 때는 그냥 클러스터부터 삭제하시고 다시 시작하는 것을 추천드립니다. ㅋㅋㅋㅋ
1-7 배포 후 Pod 상태 확인 및 문제 해결
- Pod 상태 점검
kubectl get pods명령어로 모든 Pod의 상태를 확인하세요. Pod이 정상적으로Running상태인지 확인하고,STATUS가Pending이나CrashLoopBackOff인 경우 리소스 제한 또는 설정 오류일 수 있습니다. - Pod 로그 확인
배포 중에 문제가 발생하거나 특정 Pod에서 오류가 발생할 경우 다음 명령어로 Pod의 로그를 확인할 수 있습니다.
오류 메시지와 스택 트레이스를 분석해, 잘못된 설정이 있는지, 리소스가 부족한지 등을 파악합니다.
# pod명 확인 kubectl get pods # pod 로그 확인 kubectl logs <pod-name>
- Event 확인
문제가 있는 Pod이나 서비스에서 발생한 이벤트를 통해 오류 원인을 찾을 수도 있습니다.
이 명령어를 사용해 Event 섹션에서 자세한 오류 메시지를 확인할 수 있습니다.
# pod명 확인 kubectl get pods # pod 상세 정보 확인 kubectl describe pod <pod-name>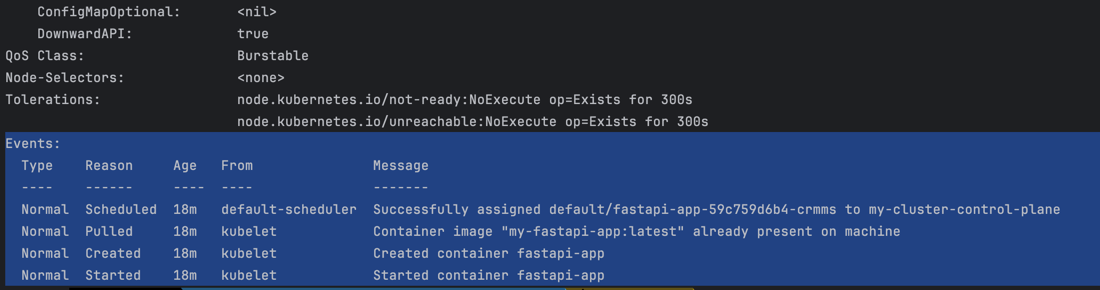
위 단계를 통해 Kubernetes 클러스터에 설정 파일을 기반으로 FastAPI 애플리케이션을 배포한 모습입니다.
2. Kubernetes 클러스터 모니터링하기
Kubernetes 클러스터에 배포한 애플리케이션이 안정적으로 작동하는지, 리소스 사용량이 적정한지 확인하기 위해 모니터링은 필수적입니다. 모니터링 방법을 단계별로 안내하겠습니다.
2-1 기본 모니터링 명령어 활용하기
배포된 리소스 상태를 간단히 점검하려면 Kubernetes의 기본 명령어들을 사용할 수 있습니다.
- Pod 상태 모니터링
Pod의STATUS열이Running인지 확인합니다.Pending이나CrashLoopBackOff상태인 경우 문제가 있을 수 있습니다.
kubectl get pods - Deployment 상태 모니터링
READY열의 숫자가 기대한 Pod 수와 일치하는지 확인합니다.
kubectl get deployments - Service 상태 모니터링
Service가 올바르게 설정되어 있는지 확인하고, 포트 및 IP 정보가 정확한지 확인합니다.
kubectl get services - Horizontal Pod Autoscaler(HPA) 상태 모니터링
TARGETS열에서 CPU와 메모리 사용률이 설정된 임계값에 맞춰 스케일 조정이 되고 있는지 확인할 수 있습니다. HPA가 정상 작동하고 있는지 주기적으로 모니터링하세요.
kubectl get hpa
2-2 리소스 사용량 모니터링하기
Kubernetes에서 Pod 및 노드의 리소스 사용량을 모니터링하려면 Metrics Server가 필요합니다. Metrics Server는 CPU와 메모리 사용량을 실시간으로 수집해주는 컴포넌트입니다.
- Pod 모니터링을 위한 metrics-server-deployment.yaml 생성
metrics-server-deployment.yaml이라는 새로운 파일을 k8s 디렉토리에 추가하여 Metric Server 설정을 포함하고--kubelet-insecure-tls플래그를 추가해 TLS 인증을 무시하도록 설정합니다.
apiVersion: apps/v1 kind: Deployment metadata: name: metrics-server namespace: kube-system labels: k8s-app: metrics-server spec: selector: matchLabels: k8s-app: metrics-server template: metadata: labels: k8s-app: metrics-server spec: containers: - name: metrics-server image: k8s.gcr.io/metrics-server/metrics-server:v0.6.1 args: - --cert-dir=/tmp - --secure-port=10250 - --kubelet-preferred-address-types=InternalIP - --kubelet-insecure-tls # TLS 인증 무시 플래그 - --kubelet-use-node-status-port ports: - containerPort: 10250 name: https volumeMounts: - name: tmp-dir mountPath: /tmp nodeSelector: kubernetes.io/os: linux serviceAccountName: metrics-server volumes: - name: tmp-dir emptyDir: {} - Metric Server 적용
작성한 metrics-server-deployment.yaml 파일을 사용하여 Metric Server를 배포합니다.
(리소스부터 반드시 먼저 다운로드해주세요)
# 모니터링을 위해 Metric Server 설치 kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml # deployment 추가(yaml을 이용해 설치한 Metric Server에 --kubelet-insecure-tls 플래그 추가) kubectl apply -f k8s/metrics-server-deployment.yaml # 추후 문제가 있을 시 삭제 방법 kubectl delete deployment metrics-server -n kube-system # 명령어를 통해 metric server 정상 실행 확인(이거 로딩되는데 1~2분 걸릴 수 있습니다만, 그 이상 걸리면 뭔가 문제가 있는거니 metric server 및 관련 deployment를 delete하고 다시 설치해주세요) kubectl get deployments -n kube-system
- Pod 리소스 사용량 확인
# Pod 리소스 사용량 확인 kubectl top pods # pod명 확인 kubectl get pods # 특정 Pod의 리소스 사용량 확인 kubectl top pod <pod-name>
배포 후 Pod 및 Service의 상태를 점검하고, 리소스 사용량에 따라 자동으로 스케일 조정이 가능하도록 설정하는 데까지 완료했습니다.
2-3 실시간 모니터링 및 시각화 도구 활용
기본 명령어 외에도 Kubernetes 모니터링 도구를 활용해 더 심도 있는 데이터를 수집하고, 시각화할 수 있습니다. 대표적인 도구로 Prometheus와 Grafana가 있습니다.
helm은 Kubernetes의 패키지 관리 도구로, Helm을 사용하면 간단하게 Prometheus와 Grafana를 설치하고 설정할 수 있습니다.
- Prometheus 설치 및 설정
- Prometheus는 Kubernetes의 리소스 사용 데이터를 수집하는 오픈 소스 모니터링 시스템입니다. Helm을 통해 Prometheus를 간단히 설치할 수 있습니다.
# helm 설치 brew install helm # Prometheus 설치 helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm install prometheus prometheus-community/kube-prometheus-stack # 설치 상태 확인 helm status prometheus # 포트포워딩을 통한 프로메테우스 접근 kubectl port-forward -n default svc/prometheus-kube-prometheus-prometheus 9090:9090 - 설치가 완료되면 Prometheus는 Kubernetes 리소스를 모니터링하고 수집된 데이터를 저장합니다.
- Prometheus는 Kubernetes의 리소스 사용 데이터를 수집하는 오픈 소스 모니터링 시스템입니다. Helm을 통해 Prometheus를 간단히 설치할 수 있습니다.
- Grafana를 통해 시각화
- Grafana는 Prometheus와 연동해 리소스 사용량 데이터를 실시간으로 시각화할 수 있습니다.
- Helm을 사용하여 Grafana를 설치합니다.
# Grafana 설치 helm repo add grafana https://grafana.github.io/helm-charts helm install grafana grafana/grafana # 설치 상태 확인 helm status grafana # kubectl admin 패스워드 확인 > 로그인할 때 쓰입니다. kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo # grafana에 접속하기 위한 포트 설정(여기선 3000port로 설정) export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}") kubectl --namespace default port-forward $POD_NAME 3000:3000 # admin 계정으로 로그인 # localhost:3000으로 접속 # username: admin, password: 위에서 확인한 패스워드 입력
- 설치 후, Kubernetes 클러스터 내에 생성된 Grafana 대시보드에 접근하여 리소스 사용량, HPA의 자동 스케일링 동작 여부 등을 시각화하여 한눈에 확인할 수 있습니다.
- Grafana 대시보드 설정
Grafana에 Prometheus 데이터를 소스로 추가하여 Kubernetes 관련 시각화 대시보드를 생성합니다.
- 데이터 소스 추가
- 먼저, Grafana에서 Prometheus를 데이터 소스로 추가해야 합니다.
- Grafana 화면에서 Connections > Data Sources로 이동하고,
Add data source를 클릭한 후Prometheus를 선택합니다. - Prometheus의 URL을 입력합니다. (기본값:
http://prometheus-kube-prometheus-prometheus.default.svc.cluster.local:9090)
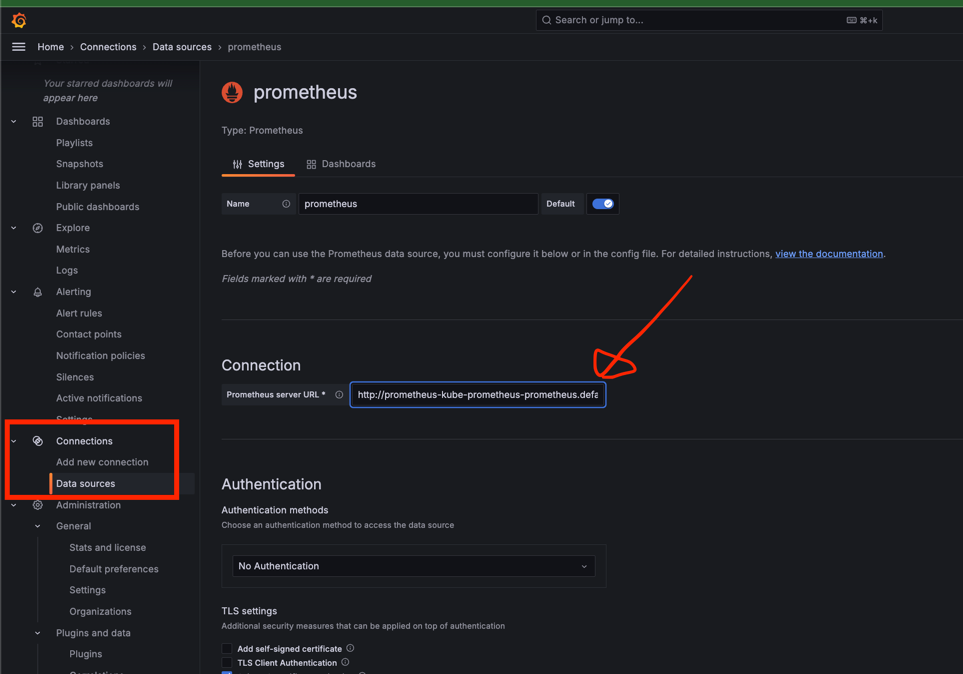
- 입력 후 제일 하단으로 내려가 Save & Test 버튼을 클릭하여 데이터 소스가 정상적으로 연결되었는지 확인합니다.
- Prometheus UI로 접속해 집계하고 싶은 쿼리 입력
- 위 방식을 따라 오셨다면
http://localhost:9090으로 접속하여 Prometheus UI에 접속할 수 있습니다. - Prometheus를 활용하면 쿼리를 입력해 강력한 데이터 집계 기능을 사용할 수 있습니다. 하지만 상대적으로 시각화 부분에서는 Grafana가 더 강력한 기능들을 제공하고 있습니다. 여기서는 Prometheus UI를 통해 쿼리를 입력하는 방법을 안내해보겠습니다.
- 각 패널에서 Prometheus 쿼리를 입력해 시각화할 데이터를 지정합니다. 예를 들어, Pod CPU 사용량을 시각화하려면 다음과 같은 쿼리를 입력합니다.
(다양한 쿼리에 대한 내용은 다른 블로그들에도 많고 ChatGPT 등을 활용하시면 더 많은 정보를 얻으실 수 있습니다.)sum(rate(container_cpu_usage_seconds_total{namespace="default", container!="POD"}[5m])) by (pod)쿼리를 입력하면 아래에 그래프가 즉시 생성됩니다.
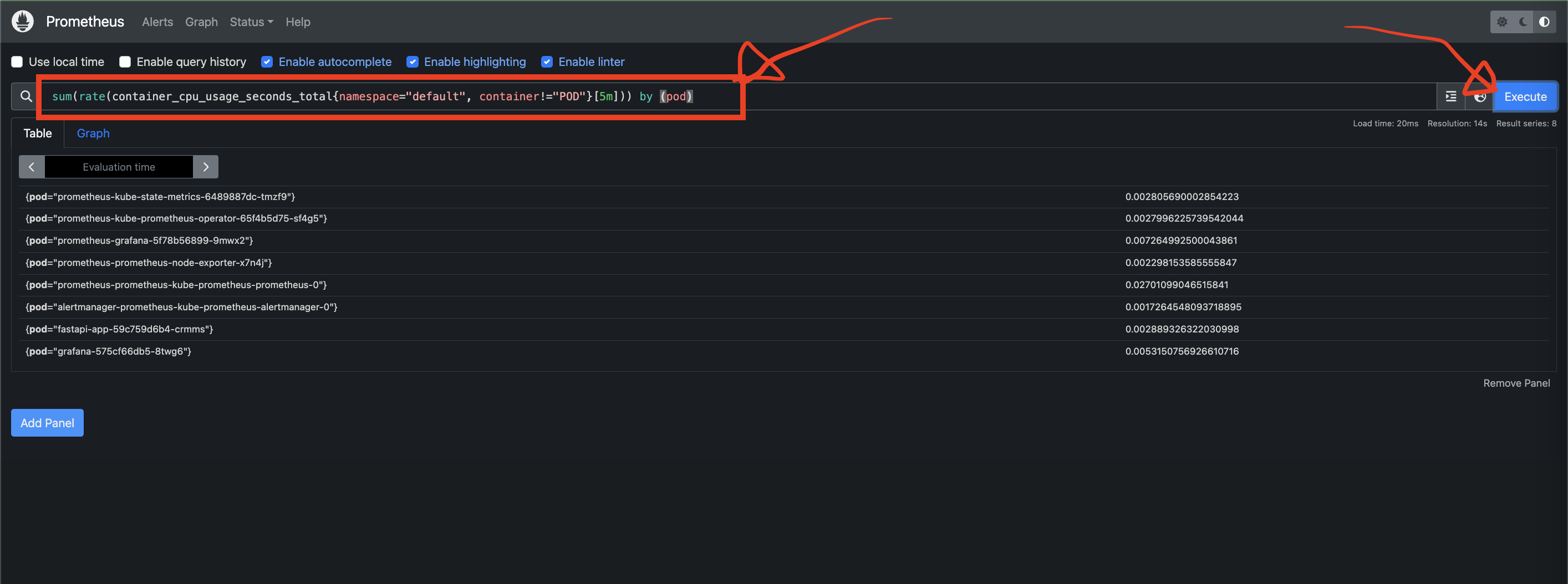
- 위 방식을 따라 오셨다면
- 새 대시보드 생성
- Grafana에서 Dashboard > New > New Dashboard를 선택하여 새로운 대시보드를 만듭니다.
- Prometheus에서 추가한 쿼리를 아래 이미지들을 따라가며 Grafana 대시보드에 추가해줍니다.
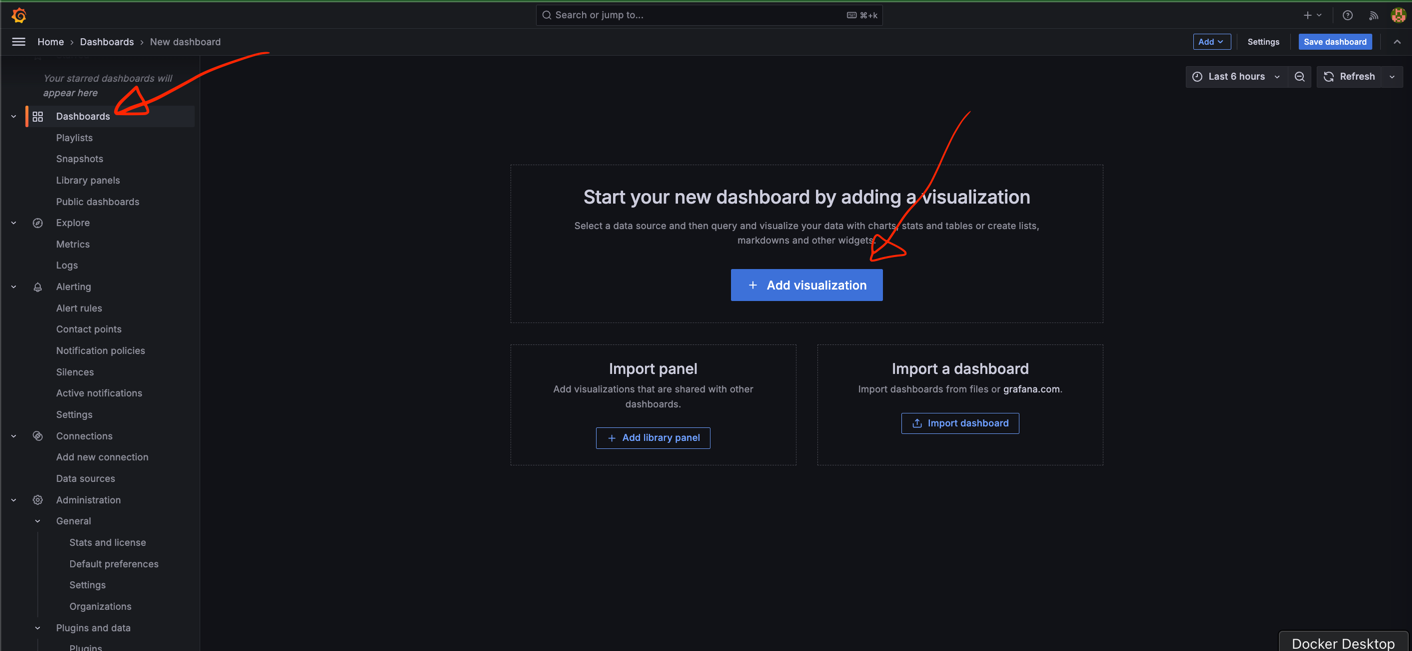
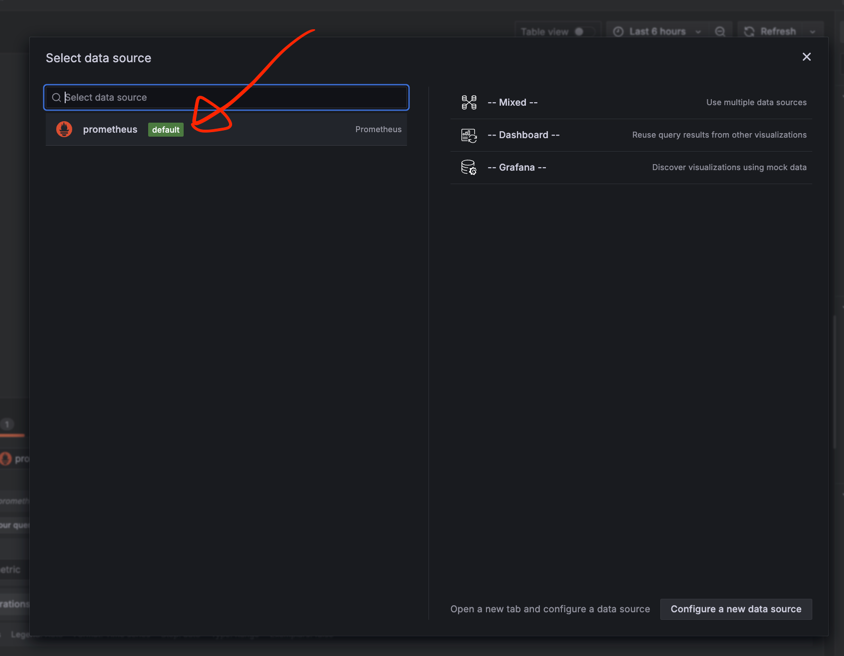
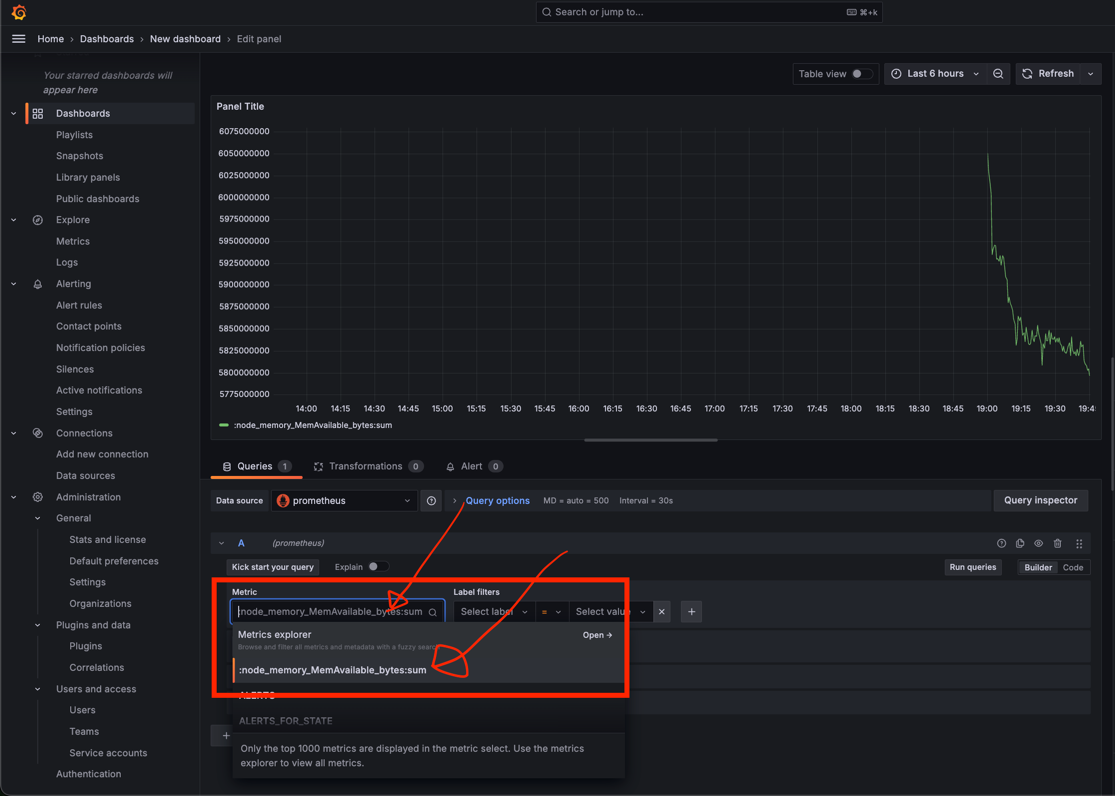
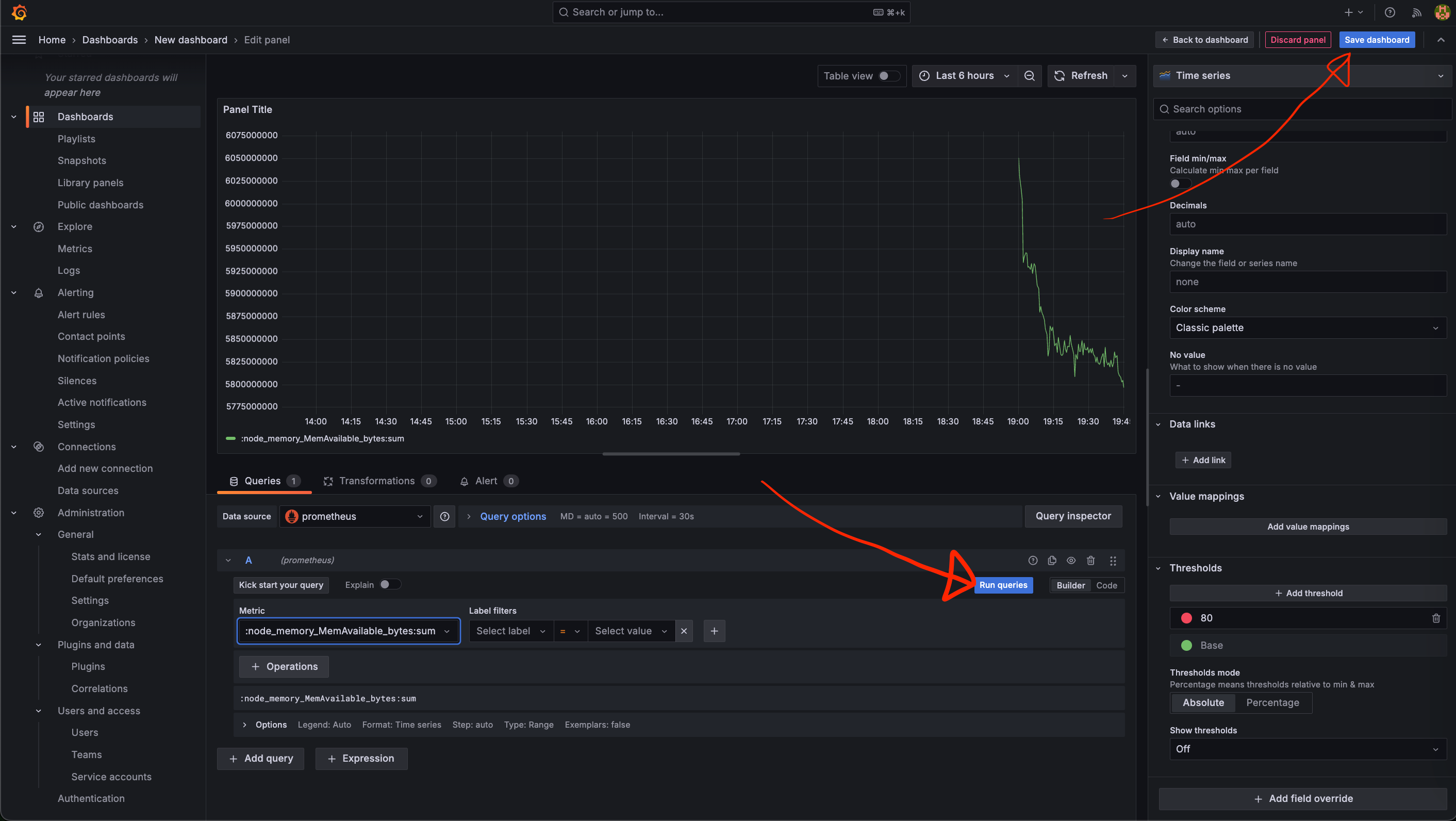
- 시각화 형식 선택
- 패널의 오른쪽에서 시각화 형식을 선택할 수 있습니다.
Time series,Gauge,Bar gauge등 원하는 형식을 선택하여 데이터가 더 잘 보이도록 설정합니다.
- 패널의 오른쪽에서 시각화 형식을 선택할 수 있습니다.
- 패널 저장 및 반복
- 설정이 완료된 패널은 저장하고, 다른 데이터를 시각화하려면 새 패널을 추가하여 쿼리를 입력하는 과정을 반복합니다.
- 이 과정을 통해 Grafana에서 원하는 Kubernetes 메트릭을 시각화할 수 있습니다. 쿼리와 시각화 형식은 필요에 맞게 커스터마이징할 수 있으며, 한 번 설정하면 대시보드에서 실시간 모니터링이 가능합니다.
- 데이터 소스 추가
2-4 알람 설정하기
모니터링은 문제가 발생했을 때 빠르게 대응하는 것이 목적이므로, 특정 상황에서 알람을 설정하는 것이 좋습니다.
예를 들어 CPU 사용량이 80% 이상이거나 Pod이 재시작될 때 알람이 울리도록 설정할 수 있습니다.
- Prometheus Alertmanager 설정
- Prometheus Alertmanager를 통해 특정 조건이 충족되면 알림을 보내도록 설정합니다.
- 예를 들어, 특정 리소스 사용률이 80%를 초과하는 경우 이메일 또는 Slack을 통해 알림을 받을 수 있습니다.
- Grafana Alert 설정
- Grafana에서도 알림 조건을 설정할 수 있습니다. 특정 대시보드에서 설정한 지표가 일정 임계값을 넘으면 알림을 받도록 설정할 수 있습니다.
이와 같은 모니터링 과정을 통해 Kubernetes 클러스터와 애플리케이션 상태를 실시간으로 점검할 수 있습니다.
개인적으로는 위처럼 알림을 설정하시더라도 항상 모니터링 도구를 활용해 눈으로 확인하시는 습관을 들이시는 것이 큰 문제로 이어질 수 있는 경우의 수를 줄이는 길이라 생각됩니다.
3. Kubernetes 클러스터 스케일링하기
Kubernetes 클러스터에서 애플리케이션의 트래픽 증가나 감소에 따라 자동으로 리소스를 확장하거나 축소하여 비용 효율적이고 안정적인 서비스를 제공할 수 있습니다. 이 과정에서는 자동 스케일링과 수동 스케일링을 모두 살펴보겠습니다.
3-1 수동 스케일링
때로는 예상 트래픽 증가나 특별한 상황에 대비해 수동으로 Pod 수를 조정하는 것이 필요할 수 있습니다.
Kubernetes에서는 간단한 명령어로 Pod 개수를 수동으로 조정할 수 있습니다.
- Deployment 수동 스케일링
이 명령어를 통해fastapi-appDeployment의 Pod 개수를 5개로 조정할 수 있습니다.--replicas옵션의 숫자를 조정하여 원하는 만큼 Pod을 늘리거나 줄일 수 있습니다.
kubectl scale deployment fastapi-app --replicas=5 - 수동 스케일링 상태 확인
READY열에 표시된 Pod 수가 목표치와 일치하는지 확인하세요. Kubernetes는 스케일 조정 후 Pod이 필요한 리소스를 사용할 수 있을 때까지 배포 상태를 지속적으로 업데이트합니다.
kubectl get deployment fastapi-app
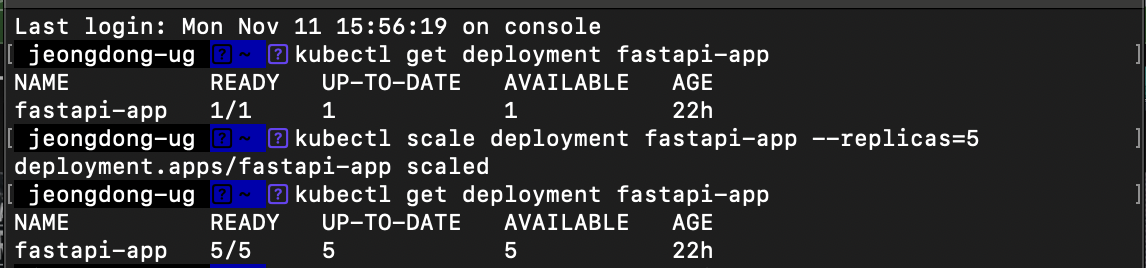
3-2 자동 스케일링 (Horizontal Pod Autoscaler)
자동 스케일링은 트래픽이 많아지거나 리소스 사용량이 증가할 때 Kubernetes가 자동으로 Pod을 확장하거나 축소하는 기능을 제공합니다. HPA(Horizontal Pod Autoscaler)를 설정하면 CPU 및 메모리 사용량을 기준으로 자동 스케일링을 구현할 수 있습니다.
- HPA 설정 파일 작성
hpa.yaml파일에 다음과 같이 정의할 수 있습니다.
minReplicas: 최소로 유지할 Pod 수를 설정합니다.maxReplicas: 최대 Pod 수를 설정해 무한 확장을 방지합니다.metrics: 스케일링 기준을 정의하며, CPU 및 메모리 사용률을 동시에 설정할 수 있습니다. 예를 들어, CPU 또는 메모리 사용률이 50%를 초과하면 스케일 아웃이 발생합니다.
- HPA 적용
kubectl apply -f k8s/hpa.yaml명령어로 HPA 설정을 적용합니다.
# HPA 설정 적용 kubectl apply -f k8s/hpa.yaml # 개괄적인 내용 확인 kubectl get hpa # 상세한 내용 확인 kubectl describe hpa fastapi-app-hpa - HPA 동작 확인
TARGETS열을 통해 설정된 CPU 및 메모리 사용률이 임계값에 도달했는지 확인할 수 있습니다. 임계값을 초과할 경우 HPA는 자동으로 스케일 아웃을 시작하며, 반대로 사용률이 낮아지면 스케일 인을 실행합니다.
# Metric Server가 정상적으로 동작하는지 확인, 현재 실행 중인 pod 정보들이 unknown이면 Metric Server가 정상적으로 동작하지 않는 것 kubectl get hpa # 또는 아래 명령어로 확인 kubectl top pods # 모니터링을 위해 Metric Server 설치 kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml # deployment 추가(yaml을 이용해 설치한 Metric Server에 --kubelet-insecure-tls 플래그 추가) kubectl apply -f k8s/metrics-server-deployment.yaml # 추후 문제가 있을 시 삭제 방법 kubectl delete deployment metrics-server -n kube-system # 명령어를 통해 metric server 정상 실행 확인(이거 로딩되는데 1~2분 걸릴 수 있습니다만, 그 이상 걸리면 뭔가 문제가 있는거니 metric server 및 관련 deployment를 delete하고 다시 설치해주세요) kubectl get deployments -n kube-system # 개괄적인 내용 확인 kubectl get hpa # 상세한 내용 확인 > kubectl describe hpa <hpa-name> kubectl describe hpa fastapi-app-hpa

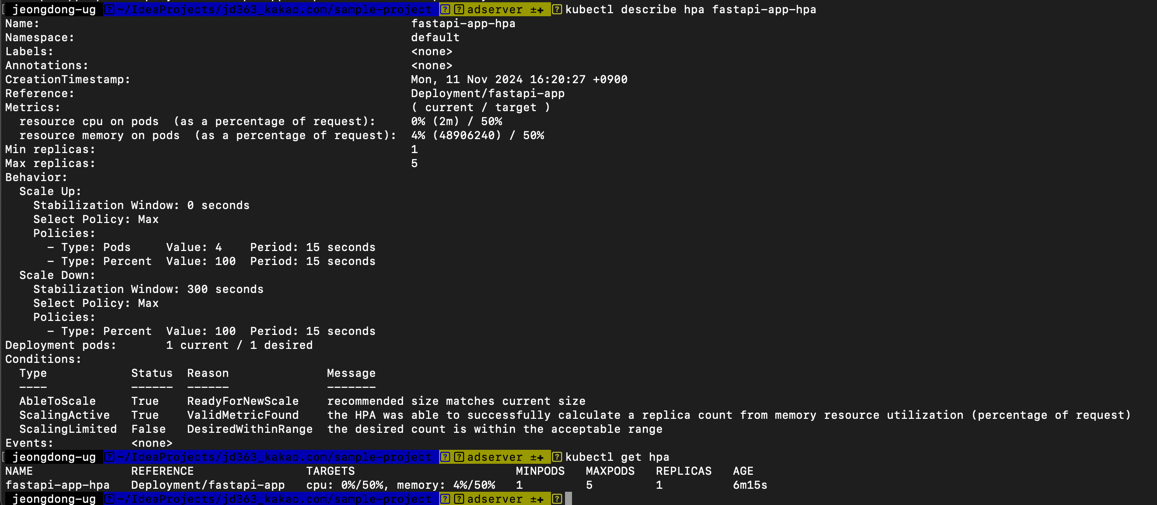
상세 내역을 살펴보면 더 다양한 내용을 확인할 수 있습니다.
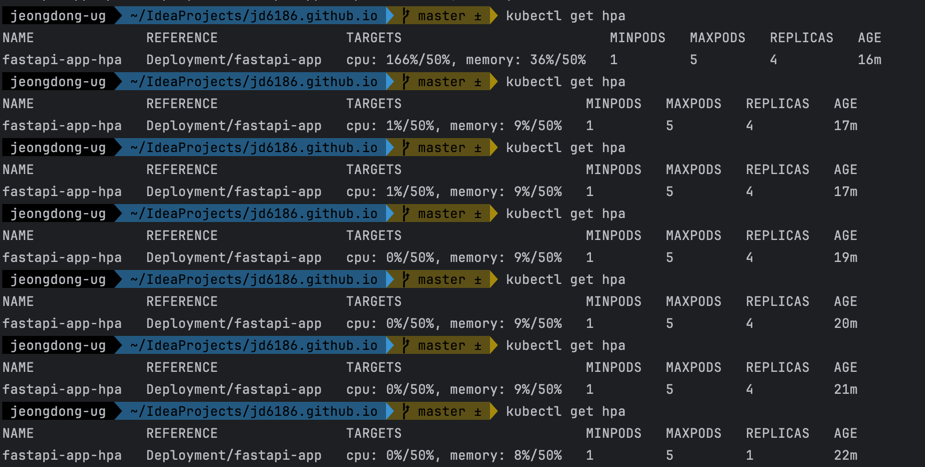
부하를 줘서 Pod를 스케일링해 보면 위 이미지와 같습니다. 위 yaml 파일에서 50%를 기준으로 설정했기 때문에 50% 이하에서는 REPLICAS가 1개, 100%이하에는 2개, 150% 이하에서는 3개, 200%이하에서는 4개로 스케일 아웃되는 방식입니다.
그래서 이미지 내 CPU 166%/50%에서는 REPLICAS가 4개로 증가되어 있는 것을 확인할 수 있습니다.
또한, AGE를 보면 17m에서 전체적인 부하가 50%이하로 내려왔기 때문에 yaml에서 지정한대로 5분이 지나서 스케일 인이 되어 REPLICAS가 1개로 되었음을 확인할 수 있습니다.
3-3 클러스터 노드 스케일링 (Cluster Autoscaler)
Pod의 개수가 증가하면서 클러스터 전체 리소스가 부족해질 경우, 노드를 추가하거나 제거하는 Cluster Autoscaler 기능을 사용할 수 있습니다. 이는 클러스터의 자동 스케일링을 통해 트래픽이나 부하에 유연하게 대응할 수 있게 합니다.
- Cluster Autoscaler 설치
GKE, EKS, AKS 등 대부분의 관리형 Kubernetes 서비스에서는 Cluster Autoscaler가 기본적으로 제공되며, 설정만 활성화하면 됩니다. 만약 클러스터에 직접 설치할 경우 다음과 같이 Helm을 통해 설치할 수 있습니다.
helm repo add autoscaler https://kubernetes.github.io/autoscaler helm install cluster-autoscaler autoscaler/cluster-autoscaler - Cluster Autoscaler 설정 확인
설치 후, Cluster Autoscaler는 자동으로 노드 수를 조절해 클러스터 리소스를 관리합니다.kubectl logs -f <cluster-autoscaler-pod-name>명령어를 사용해 로그를 확인할 수 있으며, 리소스 부족 시 노드 추가가 진행되는지 확인할 수 있습니다.
3-4 스케일링 상태 모니터링
- 스케일링 이벤트 모니터링
kubectl describe hpa fastapi-app-hpa명령어로 스케일 아웃 및 스케일 인 이벤트의 상세 로그를 확인할 수 있습니다. 이를 통해 스케일 조정이 제대로 이루어지고 있는지, 현재 설정이 적절한지 판단할 수 있습니다. - 스케일링 조건 튜닝
만약 트래픽이 급증하거나 예기치 않은 리소스 부족이 발생할 경우, HPA의 임계값을 조정하여 스케일링 조건을 최적화할 수 있습니다. 임계값 조정 시, 리소스 소비량과 응답 성능을 동시에 고려하여 설정하세요.
이와 같이 Kubernetes에서는 수동, 자동, 클러스터 스케일링 기능을 모두 제공해 다양한 상황에 대응할 수 있습니다. 각 스케일링 방법을 필요에 맞게 조합하여 클러스터의 안정성과 효율성을 유지할 수 있습니다.
4. Kubernetes 클러스터 업데이트하기
Kubernetes 클러스터에서 애플리케이션을 운영하다 보면 새로운 기능 추가나 버그 수정으로 인해 애플리케이션을 업데이트해야 할 때가 있습니다.
Kubernetes에서는 애플리케이션을 무중단으로 업데이트하기 위한 다양한 옵션을 제공합니다.
이번 섹션에서는 Kubernetes 리소스를 업데이트하는 여러 방법을 알아보겠습니다.
4-1 설정 파일을 통한 Deployment 업데이트
Kubernetes에서 애플리케이션을 업데이트하는 가장 일반적인 방법은 설정 파일을 수정한 후 다시 적용하는 것입니다.
예를 들어, 이미지를 최신 버전으로 변경하거나, 환경 변수를 추가하는 등의 수정이 필요할 때 YAML 파일을 수정하여 적용할 수 있습니다.
- 설정 파일 수정
deployment.yaml파일에서 새로운 이미지 태그나 환경 변수를 추가하는 등 필요한 업데이트 내용을 수정합니다.
예를 들어,image필드에서 애플리케이션 버전을 최신 버전으로 업데이트합니다.
```yaml spec: containers: - 변경 사항 적용
수정된 설정 파일을 클러스터에 적용합니다.
kubectl apply명령어는 현재 설정된 리소스와 비교하여 변경 사항이 있는 부분만 적용해 롤링배포를 기본으로 하기 때문에, 클러스터에 무중단으로 업데이트를 적용할 수 있습니다.(롤링 업데이트는 아래에서 설명드릴게요~)
kubectl apply -f k8s/deployment.yaml
4-2 kubectl set 명령어로 특정 설정 업데이트하기
kubectl set 명령어를 사용하면 설정 파일을 수정하지 않고도 특정 필드를 빠르게 업데이트할 수 있습니다.
예를 들어, 컨테이너 이미지를 업데이트할 때 kubectl set image 명령어를 사용할 수 있습니다.
- 이미지 업데이트
다음 명령어로fastapi-appDeployment의 컨테이너 이미지를 새로운 버전으로 즉시 업데이트합니다.
이 명령어는 설정 파일 없이도 업데이트가 가능하여, 빠르게 업데이트해야 하는 경우 유용합니다.
kubectl set image deployment/fastapi-app fastapi-app=my-fastapi-app:v2.0 - 업데이트 결과 확인
업데이트가 진행되는 동안kubectl get pods명령어로 새 버전의 Pod이 배포되는 과정을 확인할 수 있습니다. 기존 Pod이 점진적으로 교체되며 새 버전의 이미지로 업데이트됩니다.
4-3 Rolling Update 확인하기
Kubernetes의 Rolling Update 방식은 기존 Pod를 내리고 나서 다시 올리는 방식이 아니라, 새롭게 하나를 생성 후 정상 동작시 교체하는 방식으로 배포가 진행되는 것을 의미한다. 교체 시 기존 Pod는 제거되며, 새롭게 올라간 Pod가 기존 역할을 대신한다. 이를 점진적으로 교체한다고 하며, 이 때문에 서비스 중단없이 무중단 배포가 가능한 것입니다.
AWS ECS에서는 이를 ECS Blue/Green 등의 서비스로 지원하고 있습니다. 그럼 이제 아래에서 롤링 업데이트를 하는 방법에 대해 알아볼게요 ^^
- 업데이트 진행 상태 확인
업데이트 중인 Deployment의 상태를 다음 명령어로 확인할 수 있습니다.
이 명령어는 업데이트가 완료될 때까지 현재 진행 상황을 표시합니다.
kubectl rollout status deployment/fastapi-app - 업데이트 완료 확인
업데이트가 완료되면,kubectl get pods명령어로 모든 Pod이 새 버전으로 교체되었는지 확인합니다.
새로운 Pod이Running상태로 변경되었는지, 그리고READY상태가 모두 충족되었는지 확인하여 업데이트가 성공적으로 완료되었는지 검토합니다.
자세한 내용은 아래 Kubernetes 클러스터 롤링 업데이트하기에서 다루도록 하겠습니다.
4-4 환경 변수 설정 변경 시 적용방법
Kubernetes Deployment에서 특정 환경 변수만 업데이트할 필요가 있을 때는 설정 파일을 통해 환경 변수를 추가하거나 수정하여 무중단 업데이트를 진행할 수 있습니다.
- 환경 변수 추가 예시
deployment.yaml파일에 새로운 환경 변수를 추가합니다.
```yaml env:- name: APP_ENV value: “production”
- name: NEW_FEATURE_FLAG value: “enabled” ```
- 업데이트 적용
설정 파일을 적용하여 변경 사항을 반영합니다.
kubectl apply -f k8s/deployment.yaml - 변경 사항 확인
업데이트된 환경 변수가 각 Pod에 적용되었는지 확인하려면 다음 명령어를 사용합니다.
Env섹션에서 추가된 환경 변수가 올바르게 반영되었는지 확인합니다.
kubectl describe pod <pod-name>
4-5 업데이트 기록 관리 및 롤백 준비
업데이트는 항상 의도한 대로 진행되지 않을 수 있으므로, Kubernetes는 기본적으로 업데이트 기록을 보관하여 문제가 발생할 경우 이전 버전으로 되돌릴 수 있습니다.
- 업데이트 기록 확인
다음 명령어로 Deployment의 업데이트 기록을 확인할 수 있습니다.
# kubectl rollout history deployment/<deployment-name> kubectl rollout history deployment/fastapi-app - 이전 버전으로 롤백
업데이트 후 문제가 발생한 경우, 이전 버전으로 롤백하여 안정적인 상태를 유지할 수 있습니다. 이 내용은 이후 롤백하기 섹션에서 다룰 예정입니다.
이와 같은 Kubernetes 클러스터 업데이트 방법을 통해 애플리케이션을 무중단으로 안정적으로 업데이트할 수 있습니다. 각 방법을 필요에 맞게 선택하여 운영 환경에서의 안정적인 업데이트를 유지하세요.
5. Kubernetes 클러스터 롤링 업데이트하기
Kubernetes의 롤링 업데이트(Rolling Update)는 새로운 버전의 애플리케이션을 무중단으로 배포할 수 있는 기능입니다.
기존 Pod을 하나씩 새 버전으로 교체하며, 각 Pod이 준비 상태에 도달할 때까지 순차적으로 교체해 서비스 중단 없이 업데이트가 가능합니다.
이번 섹션에서는 롤링 업데이트의 원리와 적용 방법을 단계별로 살펴보겠습니다.
5-1 롤링 업데이트의 기본 원리
롤링 업데이트는 Kubernetes에서 기본 업데이트 전략으로, 다음 원리에 따라 무중단 배포를 지원합니다
- 순차 교체: 기존 Pod을 하나씩 종료하고, 새로운 Pod을 하나씩 추가합니다.
- 가용성 유지: 새로운 Pod이
Running상태로 전환되고 준비가 완료되기 전까지 기존 Pod을 유지합니다. - 최소 및 최대 Pod 수 제한: 동시에 교체되는 Pod의 수를 최소화해, 성능 저하나 서비스 중단을 방지합니다.
5-2 기본 롤링 업데이트 설정
기본적으로 Deployment의 RollingUpdate 전략은 maxUnavailable과 maxSurge 설정을 통해 교체 시 동시 Pod 개수를 제어할 수 있습니다.
maxUnavailable: 업데이트 중 비활성화될 수 있는 최대 Pod 수를 지정합니다.maxSurge: 교체 중 활성화될 수 있는 최대 Pod 수로, 필요한 리소스를 고려하여 설정할 수 있습니다.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # 교체 시점에 비활성화될 수 있는 최대 Pod 수 (1개 이하 비활성화)
maxSurge: 1 # 교체 시점에 새롭게 추가될 수 있는 최대 Pod 수 (1개 이하 활성화)
5-3 롤링 업데이트 진행하기
롤링 업데이트는 설정 파일을 수정하고 이를 적용함으로써 자동으로 진행됩니다. 새 버전의 이미지를 설정 파일에 적용해 봅시다.
- 새로운 이미지로 업데이트
deployment.yaml파일에서 이미지를 새 버전으로 업데이트합니다.
```yaml spec: containers:- name: fastapi-app image: my-fastapi-app:v2.0 # 새 버전 이미지로 업데이트 ```
- 업데이트 적용
kubectl apply명령어로 변경 사항을 클러스터에 적용하여 롤링 업데이트를 시작합니다.
kubectl apply -f k8s/deployment.yaml - 롤링 업데이트 진행 상태 확인
업데이트가 진행되는 동안 현재 상태를 확인하려면kubectl rollout status명령어를 사용할 수 있습니다.
명령어 실행 시 새로운 Pod이 준비 상태로 전환될 때까지 상태를 표시하며, 업데이트가 완료되면 완료 메시지가 나타납니다.
kubectl rollout status deployment/fastapi-app -
스케일 아웃된 상태에서 롤링 업데이트 시 진행과정 확인
스케일 아웃된 상태에서 롤링 업데이트 진행 과정을 확인하려면 kubectl get pods와 kubectl describe pod 명령어를 조합해 사용하여 어떤 파드가 내려가고, 올라왔고, 교체되었는지 확인할 수 있습니다. 다음 단계를 따라 확인할 수 있습니다.-
Pod 목록 및 상태 확인
kubectl get pods -w 명령어를 사용하여 실시간으로 파드의 상태 변화를 모니터링합니다. 이 명령어는 새로운 파드가 생성되고, 이전 버전의 파드가 종료되는 과정을 실시간으로 보여줍니다.kubectl get pods -w -
파드 상세 정보 확인
kubectl describe pod명령어를 사용하여 특정 파드의 이벤트 로그를 확인합니다. 이를 통해 해당 파드가 어떤 이유로 종료되었고, 새롭게 생성된 파드가 정상적으로 실행 중인지 여부를 확인할 수 있습니다. kubectl describe pod <pod-name> -
롤링 업데이트 히스토리 확인
kubectl rollout history deployment명령어를 사용하면 롤링 업데이트의 히스토리와 각 버전의 상태를 확인할 수 있습니다. kubectl rollout history deployment fastapi-app -
이전 버전과의 차이점 확인
kubectl rollout status와 kubectl get replicaset 명령어를 사용하여 각 ReplicaSet의 상태를 확인합니다. 이를 통해 현재와 이전 버전의 파드가 동시에 존재하는지, 각각의 ReplicaSet이 몇 개의 파드를 유지하는지 확인할 수 있습니다.kubectl rollout status deployment/fastapi-app kubectl get replicaset -
Pod 이벤트 실시간 로그 확인
kubectl logs -f명령어를 사용해 교체 중인 파드의 로그를 실시간으로 확인할 수 있습니다. 이를 통해 파드가 정상적으로 준비되고 있는지 실시간 상태를 모니터링할 수 있습니다. kubectl logs -f <pod-name>
-
이러한 방법들을 통해 롤링 업데이트 과정에서 발생하는 Pod의 상태 변화를 효과적으로 모니터링하고 분석할 수 있습니다.
5-4 롤링 업데이트 중 문제 해결
롤링 업데이트 중 문제가 발생할 경우, 진행 중인 업데이트를 일시 중단하거나 즉시 중단할 수 있습니다.
- 업데이트 일시 중단
업데이트를 중단하려면 다음 명령어를 사용합니다.
이 명령어로 업데이트가 중단된 상태에서 현재 Pod 상태를 검토할 수 있습니다.
kubectl rollout pause deployment/fastapi-app - 업데이트 재개
중단된 업데이트를 다시 시작하려면 다음 명령어를 사용하세요.
kubectl rollout resume deployment/fastapi-app - 이전 버전으로 롤백
롤링 업데이트 중 문제가 발생하여 안정성을 확보해야 할 경우, 다음 명령어로 이전 버전으로 롤백할 수 있습니다.
kubectl rollout undo deployment/fastapi-app
5-5 롤링 업데이트 완료 확인
롤링 업데이트가 완료되면 새로운 버전의 애플리케이션이 모든 Pod에 적용됩니다. 다음 명령어로 모든 Pod이 새로운 이미지로 업데이트되었는지 확인합니다.
출력된 목록에서 READY 열이 모두 설정된 개수와 일치하고, STATUS가 Running인지 확인합니다. 모든 Pod이 정상적으로 업데이트되어 가용 상태를 유지하고 있는지 점검하세요.
kubectl get pods -l app=fastapi-app
Kubernetes의 롤링 업데이트는 서비스 중단 없이 새로운 버전의 애플리케이션을 안정적으로 배포할 수 있도록 해주며, 필요 시 문제 해결 및 롤백도 지원합니다.
이러한 롤링 업데이트 전략을 통해 운영 중인 애플리케이션을 지속적으로 개선하고 업데이트할 수 있습니다.
6. Kubernetes 클러스터 롤백하기
Kubernetes에서 애플리케이션 업데이트 후 문제가 발생할 경우, 롤백 기능을 사용하여 이전 안정 버전으로 되돌릴 수 있습니다.
롤백은 예상치 못한 오류로 인해 서비스 중단을 방지하는 데 매우 중요한 역할을 합니다. 이번 섹션에서는 Kubernetes에서 롤백을 수행하는 방법과 그 원리를 단계별로 설명하겠습니다.
6-1 롤백의 기본 원리
Kubernetes는 Deployment의 업데이트 히스토리를 자동으로 저장하여, 특정 버전으로 되돌리는 기능을 지원합니다.
기본적으로 마지막 몇 개의 버전 기록을 보관하여 언제든지 이전 상태로 복원할 수 있으며, 롤백은 다음과 같은 원칙으로 동작합니다.
- 업데이트 기록 저장: Kubernetes는 업데이트된 Deployment의
revision history를 유지하여 여러 버전의 기록을 보관합니다. - 롤백 시점 선택: 문제가 발생한 시점의 직전 버전으로 롤백하여 안정성을 유지할 수 있습니다.
- 무중단 복원: 롤백 중에도 롤링 업데이트 방식을 적용해 서비스 중단 없이 이전 상태로 복원합니다.
6-2 롤백 가능한 업데이트 기록 확인하기
롤백 전에, Kubernetes가 보관 중인 Deployment의 업데이트 기록을 먼저 확인하는 것이 좋습니다. 다음 명령어로 기록된 revision들을 조회할 수 있습니다.
출력된 목록에서 각 revision은 이전에 배포된 버전을 의미하며, 이를 기반으로 롤백할 버전을 선택할 수 있습니다.
kubectl rollout history deployment/fastapi-app
6-3 롤백 수행하기
Kubernetes에서는 직전 버전으로 간단히 롤백할 수 있으며, 특정 revision을 지정하여 특정 버전으로 되돌릴 수도 있습니다.
- 직전 버전으로 롤백
다음 명령어로 마지막 성공한 버전으로 Deployment를 롤백합니다.
이 명령어는 현재 버전에서 문제가 발생했을 때 직전 버전으로 빠르게 되돌릴 수 있도록 해 줍니다.
kubectl rollout undo deployment/fastapi-app - 특정
revision으로 롤백
특정 버전으로 복원하려면-to-revision플래그와 함께 해당revision번호를 지정하여 롤백할 수 있습니다.
revision번호는kubectl rollout history명령어로 확인한 후 원하는 버전으로 지정합니다.
kubectl rollout undo deployment/fastapi-app --to-revision=2 - 롤백 진행 상태 확인
롤백이 진행되는 동안 현재 상태를 모니터링하여 롤백이 원활하게 이루어지고 있는지 확인할 수 있습니다.
이 명령어는 롤백이 완료될 때까지 현재 상태를 계속 표시하며, 모든 Pod이 준비 상태에 도달하면 롤백이 성공적으로 완료된 것입니다.
kubectl rollout status deployment/fastapi-app
6-4 롤백 확인하기
롤백이 완료된 후, 이전 상태로 돌아갔는지 확인하려면 다음과 같은 방법을 사용할 수 있습니다.
- Pod 상태 확인
STATUS가 모두Running인지, 그리고READY상태가 모두 일치하는지 확인하여 모든 Pod이 안정적인 상태인지 확인합니다.
kubectl get pods -l app=fastapi-app - 업데이트 이력 검토
롤백 후에도kubectl rollout history명령어로 업데이트 기록을 다시 확인하여 롤백된 버전이 현재 배포 중인 버전인지 재확인합니다. - 로그 및 이벤트 확인
롤백된 Pod에서 애플리케이션이 정상적으로 실행되는지 로그와 이벤트를 확인합니다.
kubectl logs <pod-name> kubectl describe pod <pod-name>
롤백은 Kubernetes의 안정적인 운영을 보장하는 중요한 기능으로, 문제가 발생할 경우 신속하게 안정적인 상태로 복원할 수 있도록 지원합니다.
롤백 과정에서 발생할 수 있는 오류와 서비스 중단을 방지하기 위해 업데이트 히스토리를 관리하고, 필요한 시점에 적절하게 복구할 수 있도록 대비하는 것이 중요합니다.
7. Kubernetes 클러스터 로깅하기
Kubernetes 클러스터에서 로그 관리는 애플리케이션의 상태와 성능을 모니터링하고 문제를 해결하는 데 매우 중요한 역할을 합니다.
특히 분산 환경에서 여러 Pod이 다양한 작업을 동시에 수행하기 때문에 효과적인 로그 관리가 필수적입니다.
이번 섹션에서는 Kubernetes 클러스터에서 로깅을 수행하는 기본적인 방법과, 외부 로깅 시스템을 활용한 확장 방법을 설명하겠습니다.
7-1 기본 로깅 명령어로 Pod 로그 확인하기
Kubernetes는 기본적으로 각 Pod과 컨테이너의 로그를 확인할 수 있는 명령어를 제공합니다. 이를 통해 특정 Pod에서 발생하는 오류나 상태를 즉시 확인할 수 있습니다.
- 단일 컨테이너 로그 확인
kubectl logs <pod-name>특정 Pod의 로그를 확인하려면 아래 명령어를 사용합니다. Pod이 여러 컨테이너를 포함하고 있을 경우,
-c옵션으로 컨테이너 이름을 지정하여 해당 컨테이너의 로그만 조회할 수 있습니다.kubectl logs <pod-name> -c <container-name> - 로그 실시간 스트리밍
로그를 실시간으로 모니터링하려면f옵션을 추가하여 새로운 로그가 출력될 때마다 자동으로 갱신됩니다.
kubectl logs -f <pod-name> - 다중 Pod 로그 확인
여러 Pod에서 동일한 애플리케이션이 실행 중인 경우,kubectl logs명령어만으로는 각 Pod의 로그를 개별적으로 확인해야 하므로 번거로울 수 있습니다.
이 경우 로그 수집 도구를 사용하여 다중 Pod의 로그를 한곳에 통합해 관리하는 것이 좋습니다.
7-2 외부 로깅 시스템을 사용한 클러스터 로깅 확장
분산된 Kubernetes 환경에서는 모든 로그를 중앙에서 관리하고 분석하는 것이 효과적입니다.
Kubernetes에서는 대표적으로 ELK Stack(Elasticsearch, Logstash, Kibana)이나 EFK Stack(Elasticsearch, Fluentd, Kibana)과 같은 외부 로깅 시스템을 통해 로그를 수집하고 시각화할 수 있습니다.
- EFK Stack 구성하기
- Elasticsearch: 로그 데이터를 저장하고 검색할 수 있는 스토리지 역할을 합니다.
- Fluentd: Kubernetes의 로그를 수집하여 Elasticsearch로 전송하는 데이터 수집기입니다.
- Kibana: Elasticsearch에 저장된 로그를 시각화하고 분석할 수 있는 대시보드 도구입니다.
- EFK 설치 및 구성
Helm을 사용하면 EFK Stack을 간편하게 설치할 수 있습니다. Helm을 이용해 Elasticsearch, Fluentd, Kibana를 클러스터에 배포합니다.
helm repo add elastic https://helm.elastic.co helm install elasticsearch elastic/elasticsearch helm install kibana elastic/kibana helm repo add fluent https://fluent.github.io/helm-charts helm install fluentd fluent/fluentd - Fluentd 설정 파일 작성
Fluentd의 설정 파일을 통해 로그 수집 경로와 전송 방식을 설정합니다. 예를 들어, 각 Pod의 로그를 Elasticsearch로 전송하도록 설정할 수 있습니다. - Kibana 대시보드에서 로그 확인
Kibana에서 Elasticsearch에 수집된 로그 데이터를 시각화하고 필터링하여 클러스터와 애플리케이션의 상태를 실시간으로 모니터링할 수 있습니다.
이를 통해 다양한 Pod에서 발생하는 로그를 한 곳에서 편리하게 관리할 수 있습니다.
7-3 애플리케이션 레벨의 구조적 로깅 도입
기본 로그 외에도 애플리케이션에서 직접 구조화된 로그를 남기는 것도 중요합니다. 예를 들어 JSON 형식으로 로그를 작성하면, 로그 분석 시스템에서 필드를 기반으로 로그를 분류하고 분석할 수 있습니다.
- JSON 포맷으로 구조적 로그 작성
FastAPI나 Django 같은 Python 애플리케이션에서는logging모듈을 사용해 JSON 형식의 로그를 작성할 수 있습니다.
import logging import json logger = logging.getLogger("my_app") logging.basicConfig(level=logging.INFO, format=json.dumps({ "timestamp": "%(asctime)s", "level": "%(levelname)s", "message": "%(message)s" })) logger.info("This is a structured log message") - 구조적 로그의 장점
JSON 형식의 구조적 로그는 키-값 쌍으로 작성되므로, 로그 분석 툴에서 필터링하거나 조건을 추가해 손쉽게 분석할 수 있습니다.
7-4 로깅 설정 최적화 및 주의 사항
로깅이 지나치게 상세하거나 불필요한 정보가 많을 경우 클러스터의 스토리지 리소스를 많이 차지할 수 있습니다. 다음과 같은 점을 고려하여 로깅을 설정하면 효율적인 로그 관리를 할 수 있습니다.
- 로그 수준 설정
개발, 테스트, 운영 환경에 따라 적절한 로그 수준(DEBUG, INFO, WARNING, ERROR, CRITICAL)을 설정하세요.
운영 환경에서는 일반적으로INFO또는WARNING수준으로 설정하여 불필요한 로그를 줄일 수 있습니다. - 로그 보존 기간 설정
Elasticsearch 등의 스토리지에 저장되는 로그 데이터의 보존 기간을 설정하여 오래된 로그는 자동으로 삭제되도록 관리하세요. 이를 통해 스토리지 리소스를 효율적으로 사용할 수 있습니다. - 로그 샘플링
트래픽이 많은 서비스에서는 모든 요청의 로그를 남기기보다는 샘플링을 통해 대표적인 로그만 수집하여 관리 부담을 줄일 수 있습니다.
이와 같이 Kubernetes 클러스터에서 로깅을 관리하면 애플리케이션 상태와 성능을 효과적으로 모니터링할 수 있습니다.
기본 명령어로 간단히 로그를 확인하고, EFK Stack과 같은 외부 로깅 시스템을 통해 로그를 통합 관리하여 클러스터의 운영 효율성을 극대화하세요.
Outro
이번 글을 통해 Kubernetes의 다양한 기능과 활용법을 이해하고, 실무에서 안정적으로 애플리케이션을 배포하고 관리하는 방법을 익히셨기를 바랍니다.
Kubernetes는 확장성과 유연성을 갖춘 도구이지만, 설정과 관리에서 놓치기 쉬운 부분도 많습니다.
따라서 단계별로 정확하게 설정을 검토하고, 모니터링과 로깅을 통해 지속적인 관리와 개선이 필요합니다.
저도 이 글에 제가 실제로 배포하면서 캡처한 사진들을 계속해서 업데이트할 예정이니 혹시나 궁금하신 점이나 추가적인 정보가 필요하시다면 언제든지 댓글로 남겨주세요.
긴 글 읽어주셔서 감사합니다! 🙏