Docker Compose를 활용한 Kafka 클러스터 구축(With. Spring Kafka)
Intro
안녕하세요 Noah입니다.
오늘은 저번 글에서 얘기했던 것 처럼 Kafka를 로컬 환경에서 설치하지 않고, Docker를 활용해 Zookeeper와 Kafka 브로커를 클러스터로 구성하는 방법을 공유하려 합니다.
Docker Compose를 사용하면 필요한 모든 서버와 미들웨어를 한번에 띄우고 관리할 수 있어, 개발 환경 설정이 훨씬 간편해집니다.
이 글에서는 Docker Compose를 사용해 Kafka 클러스터를 구성하고, Spring Kafka와 Spring Boot를 활용한 예제를 통해 실습을 진행하겠습니다.
이전 “Kafka 기본 개념정리” + 이번 “실무 적용 방법”을 모두 보시면 쉽게 이해할 수 있을 것 같습니다.
(조금 길지만 이전 글을 읽고 오시면 좋을 것 같아요 ^^)
이제부터 시작해보겠습니다.
목차
Docker Compose로 Kafka 클러스터 구성
Kafka를 운영하기 위해서는 Zookeeper와 Kafka 브로커가 필요합니다.
이번 섹션에서는 Docker Compose를 사용해 Zookeeper와 Kafka 브로커를 3대씩 띄우는 방법을 설명하겠습니다.
Docker Compose 파일 작성
우선, Docker Compose 파일을 작성합니다. 이 파일은 Zookeeper와 Kafka 브로커를 설정하는데 필요한 모든 정보를 담고 있습니다.
아래 블로그에서 작성된 docker-compose.yml 파일을 활용하고 각 설정이 어떤 내용인지 주석을 추가하였습니다. 아래 글도 확인해보시면 좋을 것 같아요
[Kafka] Docker Compose로 멀티브로커 Kafka 구성하기
# Docker Compose 파일 버전을 명시합니다. 여기서는 버전 3.8을 사용합니다.
version: '3.8'
# services 섹션은 실행할 개별 서비스를 정의합니다.
services:
# 첫 번째 Zookeeper 서비스를 정의합니다.
zookeeper-1:
# 사용할 Docker 이미지와 태그를 지정합니다. 최신 버전의 confluentinc/cp-zookeeper 이미지를 사용합니다.
image: confluentinc/cp-zookeeper:latest
# 환경 변수를 설정하여 Zookeeper 인스턴스를 구성합니다.
environment:
ZOOKEEPER_SERVER_ID: 1 # Zookeeper 서버의 ID를 설정합니다.
ZOOKEEPER_CLIENT_PORT: 2181 # 클라이언트가 연결할 포트를 지정합니다.
# Zookeeper의 Heartbeat 주기 등의 시간을 밀리초 단위로 설정합니다.
ZOOKEEPER_TICK_TIME: 2000 # Zookeeper 틱 타임을 밀리초 단위로 설정합니다.
# ZOOKEEPER_INIT_LIMIT: 5일 때, Zookeeper 서버가 초기화하는 동안 팔로워(follower)와 리더(leader) 간의 초기 동기화를 완료하는 데 허용되는 틱(tick) 수를 정의합니다. 5 * 2000 밀리초 = 10000 밀리초(10초)
ZOOKEEPER_INIT_LIMIT: 5 # 이걸 설정 안하면 Zookeeper 서버가 올라오다가 떨어지는 경우가 있습니다.
# ZOOKEEPER_SYNC_LIMIT: 2일 때, 팔로워가 리더와의 동기화를 완료하는 데 걸릴 수 있는 최대 시간은 2 * 2000 밀리초 = 4000 밀리초(4초)
ZOOKEEPER_SYNC_LIMIT: 2 # 팔로워가 리더와의 동기화를 완료할 때까지의 최대 시간을 설정합니다.
# 호스트와 컨테이너 간의 포트 매핑을 설정합니다.
ports:
- "22181:2181" # 호스트의 포트 22181을 컨테이너의 포트 2181에 매핑합니다.
# 두 번째 Zookeeper 서비스를 정의합니다.
zookeeper-2:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_SERVER_ID: 2
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ZOOKEEPER_INIT_LIMIT: 5
ZOOKEEPER_SYNC_LIMIT: 2
ports:
- "32181:2181"
# 세 번째 Zookeeper 서비스를 정의합니다.
zookeeper-3:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_SERVER_ID: 3
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ZOOKEEPER_INIT_LIMIT: 5
ZOOKEEPER_SYNC_LIMIT: 2
ports:
- "42181:2181"
# 첫 번째 Kafka 브로커 서비스를 정의합니다.
kafka-1:
image: confluentinc/cp-kafka:latest
# Kafka 브로커가 시작되기 전에 의존하는 Zookeeper 서비스를 정의합니다.
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
ports:
- 29092:29092 # 호스트의 포트 29092를 컨테이너의 포트 29092에 매핑합니다. > 여기서 사용한 Port번호를 외부에서 사용하게 되니 잘 확인해주세요.
environment:
KAFKA_BROKER_ID: 1 # Kafka 브로커의 ID를 설정합니다.
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181 # Zookeeper 연결 정보를 설정합니다.
# KAFKA_ADVERTISED_LISTENERS애 작성한 내용을 기반으로 외부에서 접속하게 되니 잘 확인해주세요.
# PLAINTEXT > 내부통신용
# PLAINTEXT_HOST > 외부통신용
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-1:9092,PLAINTEXT_HOST://localhost:29092 # 브로커의 리스너 정보를 설정합니다.
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT # 리스너 보안 프로토콜 맵을 설정합니다.
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT # 브로커 간 통신에 사용할 리스너 이름을 설정합니다.
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1 # 트랜잭션 상태 로그 복제 계수를 설정합니다.
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1 # 트랜잭션 상태 로그 최소 ISR(동기화된 복제본)의 수를 설정합니다.
# 두 번째 Kafka 브로커 서비스를 정의합니다.
kafka-2:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
ports:
- "39092:39092"
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-2:9092,PLAINTEXT_HOST://localhost:39092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
# 세 번째 Kafka 브로커 서비스를 정의합니다.
kafka-3:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
ports:
- "49092:49092"
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-3:9092,PLAINTEXT_HOST://localhost:49092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
이 Docker Compose 파일은 다음을 수행합니다
- Zookeeper 3대로 앙상블을 구성합니다.
- Kafka 브로커 3대를 설정해 고가용성을 확보합니다.
- 각 Kafka 브로커는 Zookeeper 클러스터에 연결됩니다.
ZOO_SERVERS
환경변수 중 ZOO_SERVERS 내용이 어려워 조금더 디테일하게 확인해보겠습니다.(제 기준 ㅎㅎ)
ZOOKEEPER_SERVERS: |
server.1=my-zookeeper-1:2888:3888
server.2=my-zookeeper-2:2888:3888
server.3=my-zookeeper-3:2888:3888
하나씩 뜯어보면 다음과 같습니다.
# server.주키퍼서버아이디=호스트명:포트1:포트2
server.<id>=<hostname>:<port1>:<port2>
#예시: server.1=my-zookeeper-1:2888:3888
각 부분의 의미는 다음과 같습니다
- server.id: 서버의 ID를 지정합니다. 환경변수 중 “ZOOKEEPER_SERVER_ID” 값과 대응됩니다.
- 예: server.1, server.2, server.3
- hostname: Zookeeper 서버의 호스트 이름 또는 IP 주소를 지정합니다. Docker Compose에서는 서비스 이름을 호스트 이름으로 사용할 수 있습니다.
- 예: zookeeper-1, zookeeper-2, zookeeper-3
- port1: “서버 간 통신(리더선출 등)”을 위한 포트입니다.
- 예: 2888
- port2: 서버 간 “데이터 동기화”를 위한 포트입니다.
- 예: 3888
여기서 사용되는 port들이 모두 중요한 역할을 하기 때문에, 이 부분을 잘 이해하고 있어야 합니다. ^^
Docker Compose 실행
자, 이제 진짜 실행해볼까요?
Docker Compose 파일을 작성한 후, 해당 파일이 있는 디렉토리에서 다음 명령어를 실행하여 Kafka 클러스터를 시작합니다.
# 이 명령어는 백그라운드에서 모든 컨테이너를 실행합니다.
docker-compose up -d
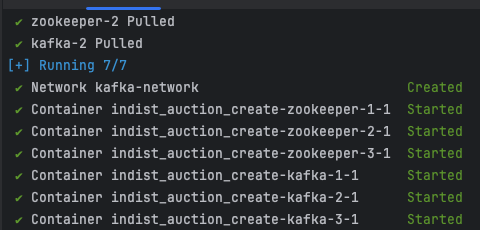
# 명령어를 사용해 모든 서비스가 정상적으로 실행되고 있는지 확인할 수 있습니다.
docker-compose ps

—
Spring Kafka로 Consumer 구현
Kafka Consumer는 특정 토픽에서 메시지를 읽어오는 역할을 합니다. Spring Kafka를 사용하여 간단한 Consumer를 구현하는 방법을 소개하겠습니다.
프로젝트 설정
먼저, Spring Boot 프로젝트를 설정합니다. build.gradle 또는 pom.xml 파일에 필요한 의존성을 추가합니다.
[Gradle]
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
implementation 'org.springframework.kafka:spring-kafka'
}
[Maven]
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>
Kafka Consumer 설정
application.yml 파일에 Kafka 설정을 추가합니다.
spring:
kafka:
consumer:
# Kafka broker 서버 목록을 설정합니다.
bootstrap-servers: localhost:29092,localhost:39093,localhost:49094
# 메시지 키를 문자열로 역직렬화합니다.
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 메시지 값을 문자열로 역직렬화합니다.
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 자동 오프셋이 어디서부터 데이터를 읽어올 것인지 설정합니다.
auto-offset-reset: latest
# 수동 커밋을 활용하고 싶을 경우 false, 기본은 auto-commit: true
enable-auto-commit: false
properties:
heartbeat.interval.ms: 1000 # heartbeat 간격을 1초로 설정
session.timeout.ms: 15000 # session timeout을 15초로 설정
max.poll.interval.ms: 300000 # 최대 poll 간격을 5분으로 설정
listener:
# poll() 메소드의 타임아웃을 설정합니다.
# 3초(3000밀리초)로 설정되어 있습니다.
poll-timeout: 3000
# 메시지 처리 후 수동으로 확인(ack)하는 방식을 사용합니다.
# MANUAL로 설정하면 직접 메시지를 확인해야 합니다. > 수동 커밋 시에는 MANUAL로 설정해주셔야만 작동합니다.
ack-mode: MANUAL
# true로 설정하면 누락된 토픽이 있으면 애플리케이션이 시작하지 않습니다.
# false로 설정되어 있으므로 누락된 토픽이 있어도 애플리케이션이 계속 실행됩니다.
missing-topics-fatal: false
# 혹시 Consumer에서 메시지를 처리후 다른 Consumer로 메시지를 다시 전달하고 싶다면, Producer 설정도 추가해주세요.
producer:
# Kafka broker 서버 목록을 설정합니다. > docker를 활용하셨을 경우에는 설정하신 port번호를 잘 보고 작성해주셔야합니다.
bootstrap-servers: localhost:29092,localhost:39093,localhost:49094
# 메시지 키를 문자열로 직렬화합니다.
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 메시지 값을 문자열로 직렬화합니다.
value-serializer: org.apache.kafka.common.serialization.StringSerializer
serializer, deserializer란?
직렬화하는 이유는 Kafka는 메시지를 바이트 배열로 저장하기 때문에, 이를 적절한 데이터 형식으로 변환하기 위해 역직렬화가 필요합니다.
auto-offset-reset
Offset을 읽어오는 설정은 다음과같은 종류가 있습니다.
- earliest: 가장 처음부터 데이터를 읽어옵니다.
- latest: 가장 최근부터 데이터를 읽어옵니다.
- none: 오프셋을 찾을 수 없을 때 예외를 발생시킵니다.
ack-mode
ack-mode는 메시지 처리 후 확인 방식을 설정합니다. 다음과 같은 옵션이 있습니다.
- RECORD: 각 레코드가 처리될 때마다 개별적으로 확인합니다. 처리된 각 메시지에 대해 acknowledge 메소드가 호출됩니다.
- BATCH: 한 번의 poll() 호출로 가져온 모든 레코드를 배치로 확인합니다. 현재 배치의 마지막 레코드에 대해 acknowledge 메소드가 호출됩니다.
- TIME: 일정 시간 간격으로 레코드를 확인합니다. 설정된 시간 간격마다 확인이 이루어집니다.
- COUNT: 일정 수의 레코드가 처리될 때마다 확인합니다. 설정된 레코드 수마다 확인이 이루어집니다.
- COUNT_TIME: 일정 수의 레코드가 처리되거나 일정 시간이 경과할 때마다 확인합니다. 설정된 레코드 수 또는 시간 간격 중 먼저 도달하는 조건에 따라 확인이 이루어집니다.
- MANUAL: 애플리케이션이 수동으로 확인을 호출합니다. 메시지 처리가 끝난 후 acknowledge 메소드를 직접 호출해야 합니다.
- MANUAL_IMMEDIATE: MANUAL과 유사하지만, 확인이 즉시 이루어집니다. acknowledge 메소드 호출 시 즉시 커밋됩니다.
Code 구현 시 몇가지 팁
기본 Consumer 구현 방법
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumerService {
@KafkaListener(topics = "my-topic", groupId = "my-group")
public void listen(String message) {
System.out.println("Received message: " + message);
// TODO - 여러분이 원하는 메시지 처리 로직을 작성합니다.
}
}
위 예제에서는 my-topic이라는 토픽에서 메시지를 읽어오는 Kafka Consumer를 구현했습니다. 메시지가 수신되면 listen 메서드가 호출됩니다.
위 코드에서 ‘KafkaListener’를 통해 원하는 topic의 원하는 groupId에 해당하는 메시지를 수신할 수 있습니다.
하지만 위와 같이 구현 시 auto-commit이 진행됩니다. 이렇게 되면 메시지 처리 중 예외가 발생했을 때 메시지를 다시 처리하기 어려울 수 있습니다.
수동 커밋 구현 방법
Spring Kafka의 Consumer 설정은 기본적으로 자동 커밋입니다.
하지만, 수동으로 커밋하는 방법을 사용하면 메시지 처리 중 예외가 발생했을 때 다양하게 메시지를 재처리할 수 있습니다.
application.yml에서 다음을 설정해줍니다.
spring:
kafka:
consumer:
...
enable-auto-commit: false
listener:
...
ack-mode: MANUAL
수동 커밋을 위해 @KafkaListener 메서드에서 Acknowledgment 객체를 사용합니다.
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;
@Service
@Slf4j
public class KafkaConsumerService {
@KafkaListener(topics = "my-topic", groupId = "my-group")
public void listen(ConsumerRecord<String, String> record, Acknowledgment acknowledgment) {
System.out.println("Received message: " + record.value());
try {
// TODO - 비즈니스 로직 수행
// ~~~
} catch (CustomException e) {
// TODO - ex_1: 재시도 시 처리 가능할 수 있는 예외 상황 처리 로직 구현 > 예외 메시지들만 처리하는 별도 consumer로 메시지 발송 등의 방법 존재
// ~~~
} catch (Exception e) {
// TODO - ex_2: 재시도 시에도 처리가 불가능한 예외상황 발생 시, 로그를 남기고 메시지 강제소비 로직 구현
log.error("The message that caused the error: {}\nException occurred while processing message: {}", record.value(), e.getMessage());
} finally {
// 수동으로 커밋
acknowledgment.acknowledge();
}
}
}
위 예제는 수동 커밋을 구현한 Kafka Consumer입니다. 메시지 처리 중 예외가 발생하면, 해당 메시지를 다시 처리하거나 로그를 남기는 등의 작업을 수행할 수 있습니다.
—
예시 코드
여러분들이 이해하실 수 있게 간단한 예시 코드를 작성해보겠습니다.
핵심은 작업을 쪼개 병렬적으로 작업을 처리해 성능을 확보한다는 것에 있습니다.
Spring Kafka를 구현하실 때는 Controller를 활용해 API를 통해 들어온 요청을 Producer로 전달하고 Producer가 Consumer에게 메시지를 전송하는 방법을 사용합니다.
자세한 아래 예시코드와 README를 확인해보시면 좋을 것 같아요.
최대한 보일러 플레이트처럼 활용 가능하시게 만들고 싶었는데 아직 부족한 부분이 많은 것 같네요. 시간이 날 때 마다 리팩토링하면서 관리해 보겠습니다~
Kafka 클러스터 구현과 Consumer 예시
위 깃헙으로 접근하시면 Producer, Consumer, Kafka 설정, Docker Compose 파일 등은 확인하실 수 있습니다.
실제 프로젝트에서는 메시지를 작은 작업 단위로 나누어 병렬적으로 처리하는 것이 중요합니다.
이렇게 하면 성능을 향상시킬 수 있고, 예외가 발생했을 때 메시지를 다시 처리할 수 있는 유연성을 확보할 수 있으니 한번 참고해보시면 좋을 것 같습니다~
—
Outro
Kafka에 대해 공부하면서 알게 된 내용을 정리하면서, 제가 처음에 막연하게 어렵게만 느껴졌던 기술이 점점 더 흥미롭고 이해하기 쉬워졌습니다.
이번 포스팅을 통해 Kafka의 기본 개념부터 설치, 주요 구성 요소들까지 다루면서 저 자신도 많은 성장을 할 수 있었습니다.
여러분들도 이 글을 통해 Kafka에 대해 좀 더 쉽게 이해하고, 실무에서 활용할 수 있는 기초 지식을 쌓을 수 있기를 바랍니다.
다음 글에서는 실제 Docker를 활용해서 Broker 3대를 띄우고 메시지를 전송, 수신하는 방법에 대해 공유하겠습니다.
(이 내용을 추후에 EC2로 옮기게 되면 그대로 사용하실 수 있게 구성해보겠습니다.)
긴글 읽어주셔서 감사합니다. 혹시 궁금한 점이나 추가적인 질문이 있다면 언제든지 댓글로 남겨주세요.
감사합니다.